%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Celebv Text
Overview :
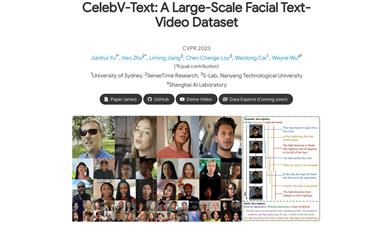
CelebV-Text is a large-scale, high-quality, and diverse face text-video dataset designed to promote research on face text-video generation tasks. The dataset contains 70,000 out-door face video clips, each accompanied by 20 text descriptions covering 40 general appearances, 5 detailed appearances, 6 lighting conditions, 37 actions, 8 emotions and 6 light directions. CelebV-Text has been validated through comprehensive statistical analysis for its superiority in video, text, and text-video correlation, and it constructs a benchmark to standardize the evaluation of face text-video generation tasks.
Target Users :
For research on face text-video generation tasks
Use Cases
Using the CelebV-Text dataset for research on face text-video generation tasks
Using the CelebV-Text dataset for analyzing face text-video correlation
Using the CelebV-Text dataset to construct a benchmark for face text-video generation tasks
Features
A large-scale face text-video dataset
70,000 outdoor face video clips
Each video clip is accompanied by 20 text descriptions
Covers 40 general appearances, 5 detailed appearances, 6 lighting conditions, 37 actions, 8 emotions, and 6 light directions
Comprehensive statistical analysis validates the superiority of the dataset
Constructs a benchmark to standardize the evaluation of face text-video generation tasks


Featured AI Tools
Celebv Text
CelebV-Text is a large-scale, high-quality, and diverse face text-video dataset designed to promote research on face text-video generation tasks. The dataset contains 70,000 out-door face video clips, each accompanied by 20 text descriptions covering 40 general appearances, 5 detailed appearances, 6 lighting conditions, 37 actions, 8 emotions and 6 light directions. CelebV-Text has been validated through comprehensive statistical analysis for its superiority in video, text, and text-video correlation, and it constructs a benchmark to standardize the evaluation of face text-video generation tasks.
AI Datasets
84.5K
Livefood
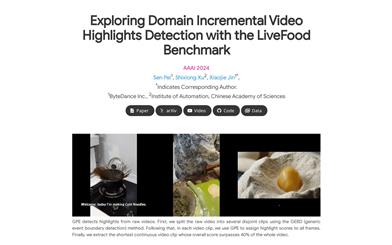
LiveFood is a dataset consisting of over 5100 gourmet videos, encompassing the four domains of ingredients, cooking, presentation, and consumption. All videos are meticulously annotated by professionals, and a strict double-checking system is employed to further ensure the quality of annotations. We have also proposed the Global Prototype Encoding (GPE) model to address the incremental learning problem, which achieves competitive performance compared to traditional techniques.
AI Datasets
66.5K