%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Best 360 Video Production Tools of 2025
Fresh Picks

Index AniSora
Index-AniSora is a top-level animation video generation model open-sourced by Bilibili, based on AniSora technology. It supports one-click generation of multiple 2D style video shots, such as anime, national creation, comic改编 animations, VTubers, animated PVs, and meme animations. The model improves the efficiency and quality of animation content production through a reinforcement learning technology framework, and its technical principles have been accepted by IJCAI2025. The openness of Index-AniSora brings new technological breakthroughs to the animation video generation field, providing powerful tools for developers and creators, and promoting further development of 2D content creation.
Video Production
40.3K

Pixverse MCP
PixVerse-MCP is a tool that allows users to access PixVerse's latest video generation models through applications that support the Model Context Protocol (MCP). This product offers features such as text-to-video generation and is suitable for creators and developers to generate high-quality videos anywhere. The PixVerse platform requires API credits, which users need to purchase themselves.
Video Production
40.3K
Fresh Picks

Vidu Q1
Vidu Q1, launched by Shengshu Technology, is a domestically produced video generation large language model designed for video creators. It supports high-definition 1080p video generation and features cinematic camera movements and start/end frame functionality. This product ranked first in the VBench-1.0 and VBench-2.0 evaluations, offering exceptional value for money at only one-tenth the price of competitors. It is suitable for film, advertising, animation, and other fields, significantly reducing production costs and improving creative efficiency.
Video Production
38.1K
Fresh Picks

Skyreels V2
SkyReels-V2 is the world's first infinite-length movie generation model using a diffusion forcing framework, released by Kunlun Wanwei's SkyReels team. The model achieves synergistic optimization by combining multimodal large language models, multi-stage pre-training, reinforcement learning, and the diffusion forcing framework, overcoming significant challenges in traditional video generation technology regarding prompt following, visual quality, motion dynamics, and video duration coordination. It not only provides content creators with powerful tools but also unlocks unlimited possibilities for video storytelling and creative expression using AI.
Video Production
40.3K
Chinese Picks

Wan2.1 FLF2V 14B
Wan2.1-FLF2V-14B is an open-source, large-scale video generation model designed to advance the field of video generation. This model excels in multiple benchmark tests, supports consumer-grade GPUs, and efficiently generates 480P and 720P videos. It performs exceptionally well in various tasks, including text-to-video and image-to-video, possessing strong visual-text generation capabilities suitable for diverse real-world applications.
Video Production
40.0K

Framepack
FramePack is an innovative video generation model designed to improve the quality and efficiency of video generation by compressing the context of input frames. Its main advantage lies in addressing the drift problem in video generation, maintaining video quality through a bidirectional sampling method, and being suitable for users who need to generate long videos. This technology is based on in-depth research and experiments on existing models to improve the stability and coherence of video generation.
Video Production
38.6K

Pusa
Pusa introduces an innovative approach to video diffusion modeling through frame-level noise control, enabling high-quality video generation suitable for various tasks (text-to-video, image-to-video, etc.). With its superior motion fidelity and efficient training process, the model offers an open-source solution for convenient video generation.
Video Production
39.2K
Skyreels A2
SkyReels-A2 is a framework based on a video diffusion transformer that allows users to synthesize and generate video content. The model, leveraging deep learning technology, provides flexible creative capabilities suitable for various video generation applications, especially in animation and special effects production. The product's advantages lie in its open-source nature and efficient model performance, making it suitable for researchers and developers. It is currently free of charge.
Video Production
40.3K

Dreamactor M1
DreamActor-M1 is a human animation framework based on Diffusion Transformer (DiT), designed to achieve fine-grained overall controllability, multi-scale adaptability, and long-term temporal consistency. The model, through blending guidance, can generate high-expressiveness and realistic human videos suitable for various scenarios from portrait to full-body animation. Its main advantages lie in its high fidelity and identity preservation, bringing new possibilities to human behavior animation.
Video Production
38.6K
English Picks
Runway Gen 4
Runway Gen-4 is an advanced AI model focused on media generation and world consistency. It can accurately generate consistent characters, locations, and objects in multiple scenarios, providing creators with unprecedented creative freedom and is suitable for various application scenarios such as film production, advertising, and product photography. This product does not require meticulous fine-tuning or additional training, simplifying the creative process and improving the quality and efficiency of video production.
Video Production
40.0K

GAIA 2
GAIA-2 is an advanced video generation model developed by Wayve, designed to provide diverse and complex driving scenarios for autonomous driving systems to improve safety and reliability. The model addresses the limitations of relying on real-world data collection by generating synthetic data, capable of creating various driving situations, including both regular and edge cases. GAIA-2 supports the simulation of various geographical and environmental conditions, helping developers quickly test and verify autonomous driving algorithms without high costs.
Video Production
39.7K

Accvideo
AccVideo is a novel and efficient distillation method that accelerates the inference speed of video diffusion models through synthetic datasets. This model can achieve an 8.5-fold speed improvement in video generation while maintaining similar performance. It uses a pre-trained video diffusion model to generate multiple effective denoising trajectories, thereby optimizing data usage and the generation process. AccVideo is especially suitable for scenarios requiring efficient video generation, such as film production and game development, and is suitable for researchers and developers.
Video Production
65.1K
Video T1
Video-T1 is a video generation model that significantly improves the quality and consistency of generated videos through test-time scaling (TTS) technology. This technology allows more computational resources to be used during inference, thereby optimizing the generation results. Compared to traditional video generation methods, TTS can provide higher generation quality and richer content expression, suitable for the digital creation field. This product is mainly aimed at researchers and developers, and the price information is not clear.
Video Production
55.2K
Fresh Picks
Step Video TI2V
Step-Video-TI2V is an advanced image-to-video model developed by Shanghai Jieyue Xingchen Intelligent Technology Co., Ltd. It is trained based on the 30B parameter Step-Video-T2V and can generate videos up to 102 frames long based on text and image input. The core advantages of this model lie in its controllable motion amplitude and controllable camera movement, balancing the dynamism and stability of the generated video. In addition, it performs exceptionally well in generating anime-style videos, making it ideal for animation creation, short video production, and other applications. The open-sourcing of this model provides strong technical support for the video generation field and promotes the development of multimodal generation technology.
Video Production
53.0K
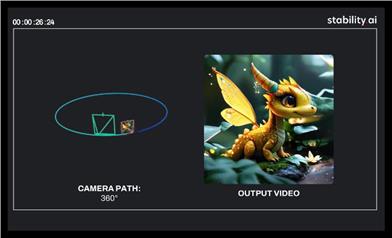
Stable Virtual Camera
Stable Virtual Camera is a 1.3B parameter general diffusion model developed by Stability AI, belonging to the Transformer image-to-video model. Its importance lies in providing technical support for novel view synthesis (NVS), capable of generating 3D-consistent new scene views based on input views and target cameras. The main advantages are the ability to freely specify the target camera trajectory, generate samples with large perspective changes that are smooth over time, maintain high consistency without additional neural radiance field (NeRF) distillation, and generate high-quality seamless loop videos up to half a minute long. The model is only freely available for research and non-commercial use, aiming to provide innovative image-to-video solutions for researchers and non-commercial creators.
Video Production
57.7K

Jellypod 2.0
Jellypod 2.0 is a brand-new AI podcast creation platform designed to provide greater creative freedom and flexibility. It not only supports audio podcasts but also generates video content, helping users enhance their podcast's visual appeal and audience engagement. Through powerful AI technology, Jellypod 2.0 allows users to create professional cover art without design skills, supports multilingual broadcasting, and offers one-click publishing to multiple platforms. This product is suitable for all types of podcast creators, providing a wealth of creative tools and publishing options to help them grow and attract audiences faster.
Video Production
55.8K
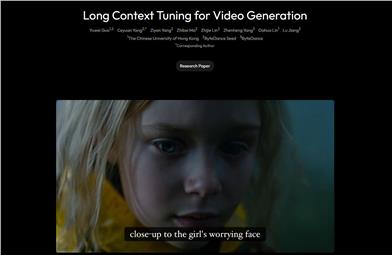
Long Context Tuning (LCT)
Long Context Tuning (LCT) aims to bridge the gap between current single-generation capabilities and real-world narrative video production. This technology directly learns scene-level consistency through data-driven methods, supporting interactive multi-shot development and synthetic generation, applicable to all aspects of video production.
Video Production
70.9K
Wan 2.1 AI
Wan 2.1 AI is an open-source large-scale video generation AI model developed by Alibaba. It supports text-to-video (T2V) and image-to-video (I2V) generation, capable of transforming simple input into high-quality video content. This model is significant in the field of video generation, greatly simplifying the video creation process, lowering the creation threshold, improving creation efficiency, and providing users with a wide variety of video creation possibilities. Its main advantages include high-quality video generation effects, smooth presentation of complex actions, realistic physical simulation, and rich artistic styles. Currently, this product is fully open-source, and users can use its basic functions for free. It is highly practical for individuals and businesses that have video creation needs but lack professional skills or equipment.
Video Production
68.2K

Symvol
Symvol is a tool focused on quickly converting text content into videos. It aims to help users understand and disseminate information more efficiently through AI and visual storytelling techniques. As a browser extension, it allows users to directly convert text content into videos on webpages without needing complex video editing knowledge. Its core technology enhances the understandability and accessibility of information, making it especially suitable for learners, content creators, and enterprise users. Symvol offers a free version, along with paid upgrade options to meet the needs of diverse users.
Video Production
60.7K

Goku AI
Goku AI is an AI video generation tool based on ByteDance's cutting-edge technology. It uses advanced AI models to quickly transform text descriptions or static images into vivid video content. This product boasts high visual fidelity and seamless motion transitions, meeting the diverse video production needs of creators, businesses, and studios. Its free trial function lowers the barrier to entry, while different tiers of paid plans offer professional users more advanced features and customized services, suitable for a wide range of video creation scenarios.
Video Production
63.2K
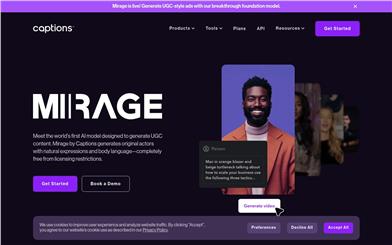
Mirage
Mirage is the first AI video generation model launched by Captions.ai, specifically designed for user-generated content (UGC) and advertising. It can quickly generate complete video content, including original virtual actors, backgrounds, voiceovers, and scripts, from simple text prompts or audio files. The core advantage of this technology lies in its complete elimination of the reliance on actors, studios, and post-production common in traditional video production, significantly reducing costs and increasing creative efficiency. Mirage provides marketers and content creators with a powerful tool to quickly generate multilingual, multi-style video content to meet the needs of various platforms and audiences.
Video Production
77.3K
MM StoryAgent
MM_StoryAgent is a story video generation framework based on the multi-agent paradigm. It combines multiple modalities such as text, images, and audio to generate high-quality story videos through a multi-stage process. The core advantage of this framework lies in its customizability; users can customize expert tools to improve the generation quality of each component. Furthermore, it provides a list of story themes and evaluation criteria to facilitate further story creation and evaluation. MM_StoryAgent is primarily aimed at creators and businesses that need to efficiently generate story videos; its open-source nature allows users to extend and optimize it according to their own needs.
Video Production
70.1K
Heygem
HeyGem is a platform focused on AI video creation, using AI technology to generate virtual avatars and voices to quickly produce high-quality videos. It is suitable for various scenarios, such as social media, education, and marketing, helping businesses or individuals efficiently output video content. Its main advantages are ease of operation, fast generation speed, professional effects, and support for multilingual and multi-style customization. The background of HeyGem is the explosive growth in demand for video content, with traditional video production being costly and time-consuming, while AI technology provides a more efficient and low-cost solution for video creation. Currently, the specific pricing and positioning of HeyGem are unclear, but based on its functions, it may target businesses and creators who need to quickly generate video content.
Video Production
108.7K
Hunyuanvideo I2V
HunyuanVideo-I2V is an open-source image-to-video generation model developed by Tencent based on the HunyuanVideo architecture. This model effectively integrates reference image information into the video generation process through image latent splicing technology, supports high-resolution video generation, and provides customizable LoRA effect training functions. This technology is of great significance in the field of video creation, helping creators quickly generate high-quality video content and improve creation efficiency.
Video Production
93.3K
Fresh Picks

Hailshell Video App
The Hailshell Video App is an AI-powered video creation tool that allows users to quickly generate videos from text descriptions or uploaded images. This product utilizes AI technology to lower the barrier to video creation, making it simple and efficient. Suitable for various scenarios such as creative expression and life recording, it offers convenience and efficiency. The product currently primarily targets mobile users and offers download options from the App Store and Android app stores.
Video Production
45.3K
PSYCHE AI
PSYCHE AI is a tool focused on generating realistic AI videos. Its core function is to quickly generate high-quality video content using AI technology. Users can choose from over 100 AI characters and 120 AI voices, creating content without any video editing experience. This product, based on advanced AI technology, provides efficient content creation solutions for businesses and individuals, particularly suitable for content marketing, education, digital employees, and personalized branding. Priced at $2-3 per video, it significantly reduces costs compared to traditional video production, and offers a free trial to lower the barrier to entry.
Video Production
55.5K
Wan2gp
Wan2GP is an improved version based on Wan2.1, aiming to provide an efficient and low-memory video generation solution for low-configuration GPU users. The model, through optimized memory management and accelerated algorithms, enables ordinary users to quickly generate high-quality video content on consumer-grade GPUs. It supports multiple tasks, including text-to-video, image-to-video, and video editing, and features a powerful video VAE architecture capable of efficiently handling 1080P videos. The emergence of Wan2GP lowers the barrier to entry for video generation technology, allowing more users to easily learn and apply it to real-world scenarios.
Video Production
74.2K
Hunyuan Video Keyframe Control Lora
HunyuanVideo Keyframe Control LoRA is an adapter for the HunyuanVideo T2V model, focusing on keyframe video generation. It modifies the input embedding layer to effectively integrate keyframe information and applies Low-Rank Adaptation (LoRA) technology to optimize linear and convolutional input layers, enabling efficient fine-tuning. This model allows users to precisely control the starting and ending frames of the generated video by defining keyframes, ensuring seamless integration with the specified keyframes and enhancing video coherence and narrative. It has significant application value in video generation, particularly excelling in scenarios requiring precise control over video content.
Video Production
62.9K
Comfyui WanVideoWrapper
ComfyUI-WanVideoWrapper provides ComfyUI nodes for WanVideo, enabling users to leverage WanVideo's functionality within the ComfyUI environment for video generation and processing. Developed in Python, this tool supports efficient content creation and video generation, suitable for users needing to quickly produce video content.
Video Production
102.1K
Wan2.1
Wan2.1 is an open-source, advanced, large-scale video generation model designed to push the boundaries of video generation technology. Through innovative spatio-temporal variational autoencoders (VAEs), scalable training strategies, large-scale data construction, and automated evaluation metrics, it significantly improves model performance and versatility. Wan2.1 supports multiple tasks, including text-to-video, image-to-video, and video editing, and can generate high-quality video content. The model has demonstrated superior performance in several benchmark tests, even surpassing some closed-source models. Its open-source nature allows researchers and developers to freely use and extend the model, making it suitable for various applications.
Video Production
69.0K
- 1
- 2
- 3
- 4
- 5
- 6
- 10
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M