%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Magical Core
MagicaLCore是一款能够在iPad上进行机器学习工作的应用。用户可以导入、组织、训练和实时测试机器学习模型,直接在设备上开发和实验模型。
模型训练与部署
40.6K

Kimi Dev
Kimi-Dev 是一款强大的开源编码 LLM,旨在解决软件工程中的问题。它通过大规模强化学习优化,确保在真实开发环境中的正确性和稳健性。Kimi-Dev-72B 在 SWE-bench 验证中实现了 60.4% 的性能,超越其他开源模型,是目前最先进的编码 LLM 之一。该模型可在 Hugging Face 和 GitHub 上下载和部署,适合开发者和研究人员使用。
代码助手
56.6K

Alphaone
AlphaOne(α1)是一种调节大型推理模型(LRMs)在测试时思维进度的通用框架。通过引入 α 时刻和动态安排慢速思维转变,α1 实现了慢速到快速推理的灵活调节。这一方法统一并推广了现有的单调缩放方法,优化了推理能力与计算效率。该产品适用于需要处理复杂推理任务的科研人员和开发者。
模型训练与部署
45.5K
Scoop Analytics
Scoop Analytics是一款AI数据分析工具,利用Agentic Analytics™技术自动运行机器学习算法,发现洞察并生成演示文稿,无需编码。其主要优点在于实时性、智能性和易用性。产品定位于为商业团队提供实时数据分析解决方案。
数据分析
40.6K
Worldpm 72B
WorldPM-72B 是一个通过大规模训练获得的统一偏好建模模型,具有显著的通用性和较强的表现能力。该模型基于 15M 偏好数据,展示了在客观知识的偏好识别方面的巨大潜力。适合用于生成更高质量的文本内容,尤其在写作领域具有重要的应用价值。
写作助手
46.6K
Audio SDS
Audio-SDS 是一个将 Score Distillation Sampling(SDS)概念应用于音频扩散模型的框架。该技术能够在不需要专门数据集的情况下,利用大型预训练模型进行多种音频任务,如物理引导的冲击声合成和基于提示的源分离。其主要优点在于通过一系列迭代优化,使得复杂的音频生成任务变得更为高效。此技术具有广泛的应用前景,能够为未来的音频生成和处理研究提供坚实基础。
音频生成
44.4K
Docsynecx By SynecX AI Labs
docsynecx是一款智能文档处理AI平台,通过AI、机器学习和OCR技术,自动化处理各种文档类型,包括发票处理、收据、提单等。该平台能够快速准确地提取、分类和组织结构化、半结构化和非结构化数据。
数据分析
45.0K

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 是一个 600 百万参数的自动语音识别(ASR)模型,旨在实现高质量的英语转录,具有准确的时间戳预测和自动标点符号、大小写支持。该模型基于 FastConformer 架构,能够高效地处理长达 24 分钟的音频片段,适合开发者、研究人员和各行业应用。
语音识别
58.5K
国外精选

Step1x Edit
Step1X-Edit 是一种实用的通用图像编辑框架,利用 MLLMs 的图像理解能力解析编辑指令,生成编辑令牌,并通过 DiT 网络解码为图像。其重要性在于能够有效满足真实用户的编辑需求,提升了图像编辑的便捷性和灵活性。
图片编辑
87.2K
Nes2net
Nes2Net 是一个为基础模型驱动的语音反欺诈任务设计的轻量级嵌套架构,具有较低的错误率,适用于音频深度假造检测。该模型在多个数据集上表现优异,预训练模型和代码已在 GitHub 上发布,便于研究人员和开发者使用。适合音频处理和安全领域,主要定位于提高语音识别和反欺诈的效率和准确性。
安全
61.8K

Easevoice Trainer
EaseVoice Trainer 是一个后端项目,旨在简化和增强语音合成与转换训练过程。该项目基于 GPT-SoVITS 进行改进,注重用户体验和系统的可维护性。其设计理念不同于原始项目,旨在提供更模块化和定制化的解决方案,适用于从小规模实验到大规模生产的多种场景。该工具可以帮助开发者和研究人员更高效地进行语音合成和转换的研究与开发。
开发与工具
97.2K

Framepack
FramePack 是一个创新的视频生成模型,旨在通过压缩输入帧的上下文来提高视频生成的质量和效率。其主要优点在于解决了视频生成中的漂移问题,通过双向采样方法保持视频质量,适合需要生成长视频的用户。该技术背景来源于对现有模型的深入研究和实验,以改进视频生成的稳定性和连贯性。
视频生成
86.4K

Genprm
GenPRM 是一种新兴的过程奖励模型(PRM),通过生成推理来提高在测试时的计算效率。这项技术能够在处理复杂任务时提供更准确的奖励评估,适用于多种机器学习和人工智能领域的应用。其主要优点是能够在资源有限的情况下优化模型性能,并在实际应用中降低计算成本。
模型训练与部署
72.9K
优质新品

Skywork OR1
Skywork-OR1是由昆仑万维天工团队开发的高性能数学代码推理模型。该模型系列在同等参数规模下实现了业界领先的推理性能,突破了大模型在逻辑理解与复杂任务求解方面的能力瓶颈。Skywork-OR1系列包括Skywork-OR1-Math-7B、Skywork-OR1-7B-Preview和Skywork-OR1-32B-Preview三款模型,分别聚焦数学推理、通用推理和高性能推理任务。此次开源不仅涵盖模型权重,还全面开放了训练数据集和完整训练代码,所有资源均已上传至GitHub和Huggingface平台,为AI社区提供了完全可复现的实践参考。这种全方位的开源策略有助于推动整个AI社区在推理能力研究上的共同进步。
AI模型
89.7K

Pusa
Pusa 通过帧级噪声控制引入视频扩散建模的创新方法,能够实现高质量的视频生成,适用于多种视频生成任务(文本到视频、图像到视频等)。该模型以其卓越的运动保真度和高效的训练过程,提供了一个开源的解决方案,方便用户进行视频生成任务。
视频生成
89.7K

Dream 7B
Dream 7B 是由香港大学 NLP 组和华为诺亚方舟实验室联合推出的最新扩散大语言模型。它在文本生成领域展现了优异的性能,特别是在复杂推理、长期规划和上下文连贯性等方面。该模型采用了先进的训练方法,具有强大的计划能力和灵活的推理能力,为各类 AI 应用提供了更为强大的支持。
AI模型
114.8K
Versatile OCR Program
该产品是一个专门设计的 OCR 系统,旨在从复杂的教育材料中提取结构化数据,支持多语言文本、数学公式、表格和图表,能够生成适用于机器学习训练的高质量数据集。该系统利用多种技术和 API,能够提供高精度的提取结果,适合学术研究和教育工作者使用。
数据分析
51.6K

Arthur Engine
Arthur Engine 是一个旨在监控和治理 AI/ML 工作负载的工具,利用流行的开源技术和框架。该产品的企业版提供更好的性能和额外功能,如自定义的企业级防护机制和指标,旨在最大化 AI 对组织的潜力。它能够有效评估和优化模型,确保数据安全与合规。
模型训练与部署
59.1K

Deepseek V3 0324
DeepSeek-V3-0324 是一个先进的文本生成模型,具有 685 亿参数,采用 BF16 和 F32 张量类型,能够支持高效的推理和文本生成。该模型的主要优点在于其强大的生成能力和开放源码的特性,使其可以被广泛应用于多种自然语言处理任务。该模型的定位是为开发者和研究人员提供一个强大的工具,帮助他们在文本生成领域取得突破。
AI模型
204.0K
RF DETR
RF-DETR 是一个基于变压器的实时目标检测模型,旨在为边缘设备提供高精度和实时性能。它在 Microsoft COCO 基准测试中超过了 60 AP,具有竞争力的性能和快速的推理速度,适合各种实际应用场景。RF-DETR 旨在解决现实世界中的物体检测问题,适用于需要高效且准确检测的行业,如安防、自动驾驶和智能监控等。
目标检测
144.9K
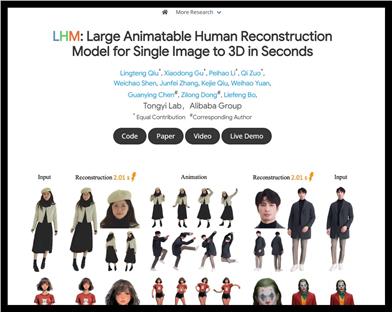
LHM
LHM(大规模可动画人类重建模型)利用多模态变压器架构进行高保真 3D 头像重建,支持从单张图像生成可动画的 3D 人类形象。该模型能够详细保留服装几何和纹理,尤其是在面部身份和细节恢复方面表现优异,适合对 3D 重建精度有较高要求的应用场景。
3D建模
62.7K

Pruna
Pruna 是一个为开发者设计的模型优化框架,通过一系列压缩算法,如量化、修剪和编译等技术,使得机器学习模型在推理时更快、体积更小且计算成本更低。产品适用于多种模型类型,包括 LLMs、视觉转换器等,且支持 Linux、MacOS 和 Windows 等多个平台。Pruna 还提供了企业版 Pruna Pro,解锁更多高级优化功能和优先支持,助力用户在实际应用中提高效率。
开发与工具
71.8K

Spatiallm
SpatialLM 是一个专为处理 3D 点云数据设计的大型语言模型,能够生成结构化的 3D 场景理解输出,包括建筑元素和对象的语义类别。它能够从单目视频序列、RGBD 图像和 LiDAR 传感器等多种来源处理点云数据,无需专用设备。SpatialLM 在自主导航和复杂 3D 场景分析任务中具有重要应用价值,显著提升空间推理能力。
3D建模
105.7K

Orpheus TTS
Orpheus TTS 是一个基于 Llama-3b 模型的开源文本转语音系统,旨在提供更加自然的人类语音合成。它具备较强的语音克隆能力和情感表达能力,适合各种实时应用场景。该产品是免费的,旨在为开发者和研究者提供便捷的语音合成工具。
文本转声音
133.0K
Firefox Translations Models
Firefox Translations Models 是由Mozilla开发的一组CPU优化的神经机器翻译模型,专为Firefox浏览器的翻译功能设计。该模型通过高效的CPU加速技术,提供快速且准确的翻译服务,支持多种语言对。其主要优点包括高性能、低延迟和对多种语言的支持。该模型是Firefox浏览器翻译功能的核心技术,为用户提供无缝的网页翻译体验。
翻译
68.7K
优质新品
Data Science Agent In Colab
Data Science Agent in Colab 是 Google 推出的一款基于 Gemini 的智能工具,旨在简化数据科学工作流程。它通过自然语言描述自动生成完整的 Colab 笔记本代码,涵盖数据导入、分析和可视化等任务。该工具的主要优点是节省时间、提高效率,并且生成的代码可修改和共享。它面向数据科学家、研究人员和开发者,尤其是那些希望快速从数据中获取洞察的用户。目前该工具免费提供给符合条件的用户。
数据分析
77.3K

3FS
3FS是一个专为AI训练和推理工作负载设计的高性能分布式文件系统。它利用现代SSD和RDMA网络,提供共享存储层,简化分布式应用开发。其核心优势在于高性能、强一致性和对多种工作负载的支持,能够显著提升AI开发和部署的效率。该系统适用于大规模AI项目,尤其在数据准备、训练和推理阶段表现出色。
开发与工具
52.2K
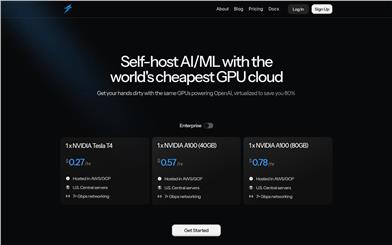
Thunder Compute
Thunder Compute是一个专注于AI/ML开发的GPU云服务平台,通过虚拟化技术,帮助用户以极低的成本使用高性能GPU资源。其主要优点是价格低廉,相比传统云服务提供商可节省高达80%的成本。该平台支持多种主流GPU型号,如NVIDIA Tesla T4、A100等,并提供7+ Gbps的网络连接,确保数据传输的高效性。Thunder Compute的目标是为AI开发者和企业降低硬件成本,加速模型训练和部署,推动AI技术的普及和应用。
开发平台
51.3K
Olmocr
olmOCR是由Allen Institute for Artificial Intelligence (AI2)开发的一个开源工具包,旨在将PDF文档线性化,以便用于大型语言模型(LLM)的训练。该工具包通过将PDF文档转换为适合LLM处理的格式,解决了传统PDF文档结构复杂、难以直接用于模型训练的问题。它支持多种功能,包括自然文本解析、多版本比较、语言过滤和SEO垃圾信息移除等。olmOCR的主要优点是能够高效处理大量PDF文档,并通过优化的提示策略和模型微调,提高文本解析的准确性和效率。该工具包适用于需要处理大量PDF数据的研究人员和开发者,尤其是在自然语言处理和机器学习领域。
开发与工具
82.8K
Tensorpool
TensorPool 是一个专注于简化机器学习模型训练的云 GPU 平台。它通过提供一个直观的命令行界面(CLI),帮助用户轻松描述任务并自动处理 GPU 的编排和执行。TensorPool 的核心技术包括智能的 Spot 节点恢复技术,能够在抢占式实例被中断时立即恢复作业,从而结合了抢占式实例的成本优势和按需实例的可靠性。此外,TensorPool 还通过实时多云分析选择最便宜的 GPU 选项,用户只需为实际执行时间付费,无需担心闲置机器带来的额外成本。TensorPool 的目标是让开发者无需花费大量时间配置云提供商,从而提高机器学习工程的速度和效率。它提供个人计划和企业计划,个人计划每周提供 $5 的免费信用额度,而企业计划则提供更高级的支持和功能。
模型训练与部署
47.7K
- 1
- 2
- 3
- 4
- 5
- 6
- 10
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.2K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.7K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
83.4K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.3K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
78.9K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
651.1K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M