%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
产品特色
像撰写文档一样创建音频
编辑文字而非波形
切换演讲者
调整发音
提供高质量的AI语音
流量来源
| 直接访问 | 26.13% | 外链引荐 | 49.96% | 邮件 | 0.07% |
| 自然搜索 | 19.77% | 社交媒体 | 3.40% | 展示广告 | 0.48% |
最新流量情况
| 月访问量 | 648 |
| 平均访问时长 | 137.80 |
| 每次访问页数 | 4.33 |
| 跳出率 | 41.85% |
总流量趋势图
地理流量分布情况
| 月访问量 | 648 |
| 越南 | 87.96% |
| 美国 | 6.19% |
| 巴西 | 5.86% |
地理流量分布全球图
同类开源产品

Chatterbox AI
Chatterbox 是 Resemble AI 推出的第一个开源生产级文本转语音 (TTS) 模型,具有卓越的性能和稳定性。它经过与顶尖闭源系统的比较,展现出更优的效果。该模型的独特之处在于它支持情感夸张控制,适用于制作视频、游戏、AI 代理等多种场景。Chatterbox 的价格竞争力强,同时提供超低延迟,适合生产使用。
文本转声音
国外精选
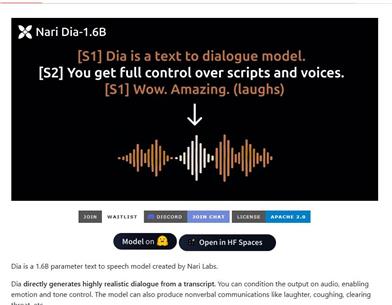
Dia AI
Dia 是一个由 Nari Labs 开发的文本到语音(TTS)模型,具有 1.6 亿参数,能够直接从文本生成高度逼真的对话。该模型支持情感和语调控制,并能够生成非言语交流,如笑声和咳嗽。它的预训练模型权重托管在 Hugging Face 上,适用于英语生成。此产品对于研究和教育用途至关重要,能够推动对话生成技术的发展。
文本转声音

Orpheus TTS
Orpheus TTS 是一个基于 Llama-3b 模型的开源文本转语音系统,旨在提供更加自然的人类语音合成。它具备较强的语音克隆能力和情感表达能力,适合各种实时应用场景。该产品是免费的,旨在为开发者和研究者提供便捷的语音合成工具。
文本转声音

Spark TTS
Spark-TTS 是一种基于大语言模型的高效文本到语音合成模型,具有单流解耦语音令牌的特性。它利用大语言模型的强大能力,直接从代码预测的音频进行重建,省略了额外的声学特征生成模型,从而提高了效率并降低了复杂性。该模型支持零样本文本到语音合成,能够跨语言和代码切换场景,非常适合需要高自然度和准确性的语音合成应用。它还支持虚拟语音创建,用户可以通过调整参数(如性别、音高和语速)来生成不同的语音。该模型的背景是为了解决传统语音合成系统中效率低下和复杂性高的问题,旨在为研究和生产提供高效、灵活且强大的解决方案。目前,该模型主要面向学术研究和合法应用,如个性化语音合成、辅助技术和语言研究等。
文本转声音

Llasa
Llasa是一个基于Llama框架的文本到语音(TTS)基础模型,专为大规模语音合成任务设计。该模型利用16万小时的标记化语音数据进行训练,具备高效的语言生成能力和多语言支持。其主要优点包括强大的语音合成能力、低推理成本和灵活的框架兼容性。该模型适用于教育、娱乐和商业场景,能够为用户提供高质量的语音合成解决方案。目前该模型在Hugging Face上免费提供,旨在推动语音合成技术的发展和应用。
文本转声音

Indextts
IndexTTS 是一种基于 GPT 风格的文本到语音(TTS)模型,主要基于 XTTS 和 Tortoise 进行开发。它能够通过拼音纠正汉字发音,并通过标点符号控制停顿。该系统在中文场景中引入了字符-拼音混合建模方法,显著提高了训练稳定性、音色相似性和音质。此外,它还集成了 BigVGAN2 来优化音频质量。该模型在数万小时的数据上进行训练,性能超越了当前流行的 TTS 系统,如 XTTS、CosyVoice2 和 F5-TTS。IndexTTS 适用于需要高质量语音合成的场景,如语音助手、有声读物等,其开源性质也使其适合学术研究和商业应用。
文本转声音
Zonos
Zonos 是一个先进的文本到语音模型,支持多种语言,能够根据文本提示和说话者嵌入或音频前缀生成自然语音。它还支持语音克隆,只需几秒钟的参考音频即可准确复制说话者的声音。该模型具有高质量的语音输出(44kHz),并允许对语速、音调变化、音频质量和情绪(如快乐、恐惧、悲伤和愤怒)进行精细控制。Zonos 提供了 Python 和 Gradio 接口,方便用户快速上手,并支持通过 Docker 部署。该模型在 RTX 4090 上的实时因子约为 2 倍,适合需要高质量语音合成的应用场景。
文本转声音
Zonos V0.1 Hybrid
Zonos-v0.1-hybrid 是由 Zyphra 开发的一款开源文本转语音模型,它能够根据文本提示生成高度自然的语音。该模型经过大量英语语音数据训练,采用 eSpeak 进行文本归一化和音素化,再通过变换器或混合骨干网络预测 DAC 令牌。它支持多种语言,包括英语、日语、中文、法语和德语,并且可以对生成语音的语速、音调、音频质量和情绪等进行精细控制。此外,它还具备零样本语音克隆功能,仅需 5 到 30 秒的语音样本即可实现高保真语音克隆。该模型在 RTX 4090 上的实时因子约为 2 倍,运行速度较快。它还配备了易于使用的 gradio 界面,并且可以通过 Docker 文件简单安装和部署。目前,该模型在 Hugging Face 上提供,用户可以免费使用,但需要自行部署。
文本转声音
Llasa 1B
Llasa-1B 是一个由香港科技大学音频实验室开发的文本转语音模型。它基于 LLaMA 架构,通过结合 XCodec2 代码本中的语音标记,能够将文本转换为自然流畅的语音。该模型在 25 万小时的中英文语音数据上进行了训练,支持从纯文本生成语音,也可以利用给定的语音提示进行合成。其主要优点是能够生成高质量的多语言语音,适用于多种语音合成场景,如有声读物、语音助手等。该模型采用 CC BY-NC-ND 4.0 许可证,禁止商业用途。
文本转声音
替代品
Voispark
VoiSpark是一个AI语音生成平台,能生成逼真的文本转语音,克隆声音,并为视频、播客等定制独特AI声音。该平台具有100%免费试用。
文本转声音
Voicss
Voicss是一款AI音轨去除器,能够智能分离音乐中的人声和背景音乐,适用于音乐编辑、卡拉OK制作等领域,无需下载软件。
音频生成
Untitledpen
UntitledPen 是一个利用最先进的GPT模型进行音频生成的工具,可以为您的内容创建最逼真的人类声音。它能够将文字转换为自然语音,适用于播客、视频、演讲等多种场景。
文本转声音
Chatterbox AI
Chatterbox 是 Resemble AI 推出的第一个开源生产级文本转语音 (TTS) 模型,具有卓越的性能和稳定性。它经过与顶尖闭源系统的比较,展现出更优的效果。该模型的独特之处在于它支持情感夸张控制,适用于制作视频、游戏、AI 代理等多种场景。Chatterbox 的价格竞争力强,同时提供超低延迟,适合生产使用。
文本转声音
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成

Echopod
EchoPod是一个利用人工智能将文章、博客和故事转换为专业品质播客的平台。其重要性在于可以帮助用户扩大影响力,提升受众参与度,无需录音室即可实现播客制作。EchoPod为Adformatie的数字媒体未来打开了无限可能。
文本转声音
Audio SDS
Audio-SDS 是一个将 Score Distillation Sampling(SDS)概念应用于音频扩散模型的框架。该技术能够在不需要专门数据集的情况下,利用大型预训练模型进行多种音频任务,如物理引导的冲击声合成和基于提示的源分离。其主要优点在于通过一系列迭代优化,使得复杂的音频生成任务变得更为高效。此技术具有广泛的应用前景,能够为未来的音频生成和处理研究提供坚实基础。
音频生成
Audiox
Audiox是一款利用AI技术生成专业音频的工具,无需音乐知识,可快速创建令人惊叹的音乐和声音效果。其主要优点包括创作便捷、音质优良、使用简单,适用于音乐制作、视频制作、声效设计等领域。
音频生成
Createwise AI
CreateWise AI 是一款利用人工智能技术为播客提供内容生成服务的工具。其主要优点在于快速生成节目笔记、剪辑和亮点,帮助节目制作者节省大量时间和精力。产品定位于为播客创作者提供便捷而高效的内容生成解决方案。
音频生成