%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


Joyhallo
简介 :
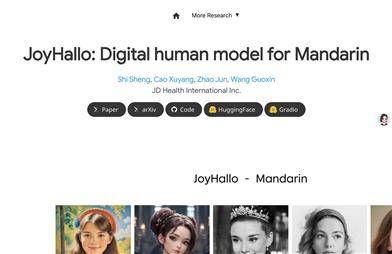
JoyHallo是一个数字人模型,专为普通话视频生成而设计。它通过收集来自京东健康国际有限公司员工的29小时普通话视频,创建了jdh-Hallo数据集。该数据集覆盖了不同年龄和说话风格,包括对话和专业医疗话题。JoyHallo模型采用中国wav2vec2模型进行音频特征嵌入,并提出了一种半解耦结构来捕捉唇部、表情和姿态特征之间的相互关系,提高了信息利用效率,并加快了推理速度14.3%。此外,JoyHallo在生成英语视频方面也表现出色,展现了卓越的跨语言生成能力。
需求人群 :
目标受众包括视频制作者、内容创作者、医疗教育工作者以及需要生成多语言视频的企业和研究机构。JoyHallo的跨语言生成能力和对普通话的优化使其特别适合需要生成高质量普通话视频的用户。
使用场景
用于生成教育视频,辅助语言学习。
在医疗领域,生成专业的医疗教育视频。
用于生成娱乐视频,增加内容创作的多样性。
产品特色
音频驱动视频生成:能够根据音频生成相应的视频内容。
普通话视频生成:专门针对普通话的复杂唇部运动进行优化。
跨语言生成能力:同时支持生成英语和普通话视频。
多样化数据集:包含不同年龄和说话风格的数据集。
半解耦结构:优化特征之间的关系,提高信息利用效率。
加速推理速度:通过结构优化,推理速度提升了14.3%。
医疗和对话内容:数据集涵盖医疗和日常对话内容。
使用教程
访问JoyHallo的官方网站。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
阅读产品介绍和功能说明。
下载并安装所需的软件或插件。
导入或录制音频文件,准备生成视频。
根据需要选择视频生成的语言和风格。
调整视频生成的参数,如唇部运动、表情等。
开始视频生成过程,并等待生成完成。
预览生成的视频,并进行必要的编辑或调整。
导出或分享生成的视频内容。












精选AI产品推荐

Sora
Sora是一个基于大规模训练的文本控制视频生成扩散模型。它能够生成长达1分钟的高清视频,涵盖广泛的视觉数据类型和分辨率。Sora通过在视频和图像的压缩潜在空间中训练,将其分解为时空位置补丁,实现了可扩展的视频生成。Sora还展现出一些模拟物理世界和数字世界的能力,如三维一致性和交互,揭示了继续扩大视频生成模型规模来发展高能力模拟器的前景。
AI视频生成
17.2M

Animate Anyone
Animate Anyone旨在通过驱动信号从静态图像生成角色视频。我们利用扩散模型的力量,提出了一个专为角色动画量身定制的新框架。为了保持参考图像中复杂外观特征的一致性,我们设计了ReferenceNet来通过空间注意力合并详细特征。为了确保可控性和连续性,我们引入了一个高效的姿势指导器来指导角色的动作,并采用了一种有效的时间建模方法,以确保视频帧之间的平滑跨帧过渡。通过扩展训练数据,我们的方法可以为任意角色制作动画,与其他图像到视频方法相比,在角色动画方面取得了出色的结果。此外,我们在时尚视频和人类舞蹈合成的基准上评估了我们的方法,取得了最先进的结果。
AI视频生成
11.8M