%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

使用场景
社交媒体情绪分析,快速判断用户评论的情感倾向。
产品评论分类,自动将用户反馈归类为正面或负面。
新闻文章主题分类,将新闻自动分发到相应的主题栏目。
产品特色
专注于CPU执行,使用高效的模型生成嵌入。
使用余弦相似度进行文本分类,无需微调。
支持多分类器执行,共享同一模型的嵌入。
支持模型训练和导出,方便未来使用。
可以将模型发布到HuggingFace模型库。
支持从目录或HuggingFace加载预训练模型。
提供类预测功能,包括单条和批量预测。
使用教程
安装fastc库:通过Python的包管理工具pip安装fastc。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
准备数据集:收集并整理用于训练分类器的文本数据。
训练模型:使用fastc提供的SentenceClassifier类来训练文本分类器。
保存模型:训练完成后,使用save_model方法保存模型以供后续使用。
加载模型:通过SentenceClassifier类加载本地或HuggingFace上的预训练模型。
进行预测:使用predict_one或predict方法对新文本进行情感分类预测。


精选AI产品推荐
中文精选
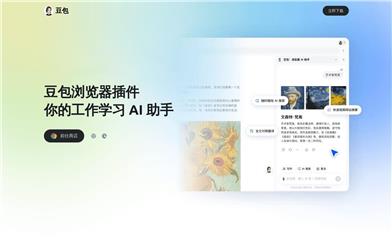
豆包浏览器插件
豆包浏览器插件旨在通过AI技术提升用户的工作效率和学习效率。它具备快速视频与一键从网页、PDF和视频中总结并生成亮点的功能,同时支持在网页任意地方划词进行全方位AI搜索。此外,它还提供全文对照翻译功能,帮助用户在阅读外文资料时更轻松地理解内容。豆包插件的设计理念是将AI技术与日常使用场景相结合,让用户在进行网页浏览、文档阅读和视频观看时能够更加便捷地获取信息和知识。
AI生产力工具
438.3K
优质新品
豆包桌面 AI 助手
豆包桌面 AI 助手是一款集成了多种 AI 功能的桌面应用程序,豆包电脑版客户端旨在提升用户的工作和学习效率。它通过 AI 划词翻译、搜索、AI 伴读 PDF 等功能,帮助用户快速获取信息,节省时间,提高生产力。产品由北京春田知韵科技有限公司开发,拥有简洁的界面和强大的功能,是现代办公和学习的得力助手。
AI生产力工具
320.2K