%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
ZH
使用场景
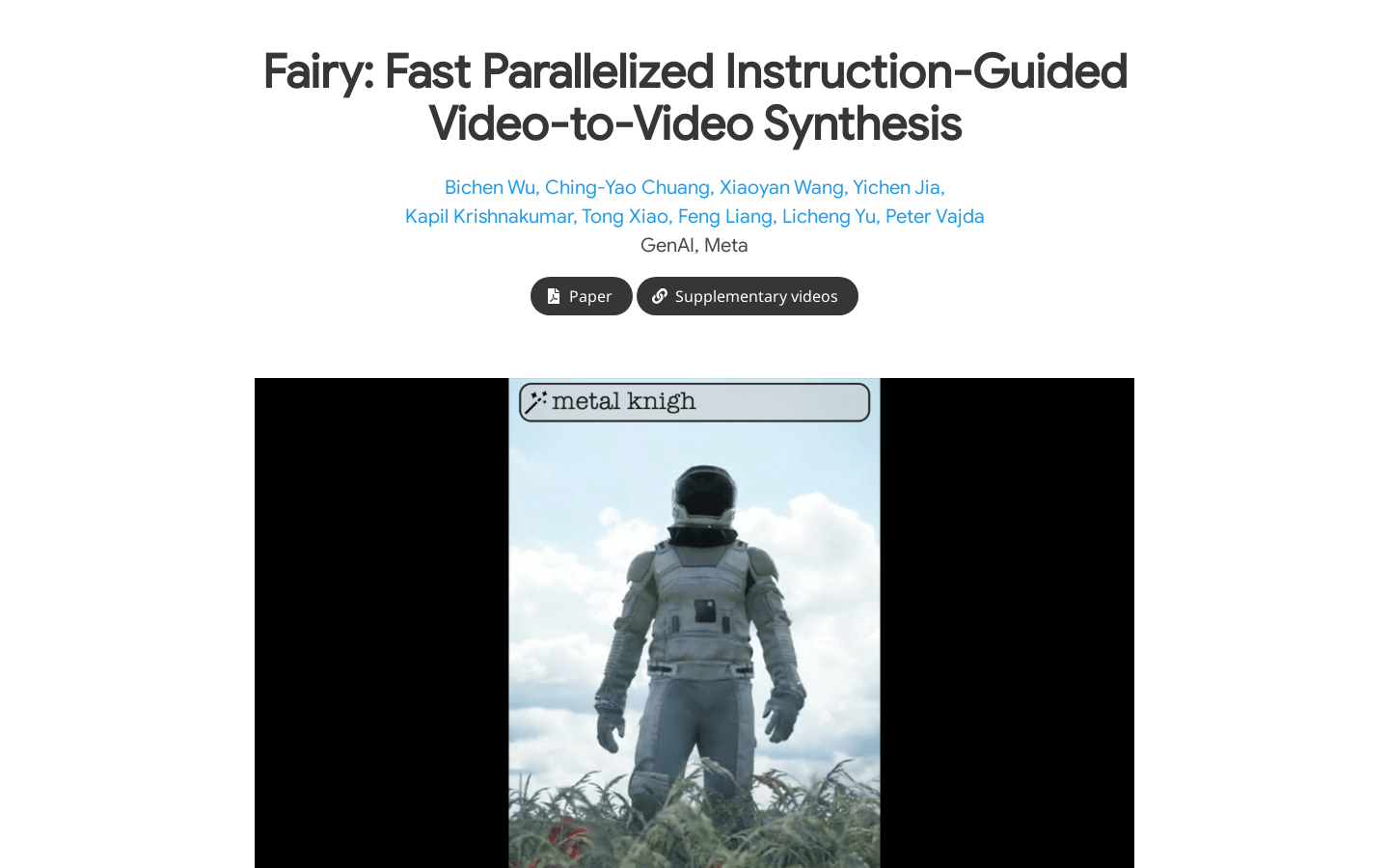
角色或物体转换视频合成
风格化视频效果制作
长视频生成
产品特色
基于锚的跨帧注意机制
高保真度视频合成
时间连贯性提升
数据增强策略
流量来源
| 直接访问 | 0.00% | 外链引荐 | 0.00% | 邮件 | 0.00% |
| 自然搜索 | 0.00% | 社交媒体 | 0.00% | 展示广告 | 0.00% |
最新流量情况
| 月访问量 | 0 |
| 平均访问时长 | 0.00 |
| 每次访问页数 | 0.00 |
| 跳出率 | 0 |
总流量趋势图
同类开源产品

Hallo2
Hallo2是一种基于潜在扩散生成模型的人像图像动画技术,通过音频驱动生成高分辨率、长时的视频。它通过引入多项设计改进,扩展了Hallo的功能,包括生成长时视频、4K分辨率视频,并增加了通过文本提示增强表情控制的能力。Hallo2的主要优点包括高分辨率输出、长时间的稳定性以及通过文本提示增强的控制性,这使得它在生成丰富多样的肖像动画内容方面具有显著优势。
AI图像生成

Comfygen
ComfyGen 是一个专注于文本到图像生成的自适应工作流系统,它通过学习用户提示来自动化并定制有效的工作流。这项技术的出现,标志着从使用单一模型到结合多个专业组件的复杂工作流的转变,旨在提高图像生成的质量。ComfyGen 背后的主要优点是能够根据用户的文本提示自动调整工作流,以生成更高质量的图像,这对于需要生成特定风格或主题图像的用户来说非常重要。
AI图像生成

Comfyui Fluxtapoz
ComfyUI-Fluxtapoz是一个为Flux在ComfyUI中编辑图像而设计的节点集合。它允许用户通过一系列节点操作来对图像进行编辑和风格转换,特别适用于需要进行图像处理和创意工作的专业人士。这个项目目前是开源的,遵循GPL-3.0许可协议,意味着用户可以自由地使用、修改和分发该软件,但需要遵守开源许可的相关规定。
AI图像生成

Toy Box Flux
Toy Box Flux是一个基于AI生成图像训练的3D渲染模型,它结合了现有的3D LoRA模型和Coloring Book Flux LoRA的权重,形成了独特的风格。该模型特别适合生成具有特定风格的玩具设计图像。它在物体和人物主体上表现最佳,动物的表现则因训练图像中的数据不足而不稳定。此外,该模型还能提高室内3D渲染的真实感。计划在v2版本中通过混合更多生成的输出和预先存在的输出来加强这种风格的一致性。
AI图像生成

Disenvisioner
DisEnvisioner是一种先进的图像生成技术,它通过分离和增强主题特征来生成定制化的图像,无需繁琐的调整或依赖多张参考图片。该技术有效地区分并增强了主题特征,同时过滤掉了不相关的属性,实现了在编辑性和身份保持方面的卓越个性化质量。DisEnvisioner的研究背景基于当前图像生成领域对于从视觉提示中提取主题特征的需求,它通过创新的方法解决了现有技术在这一领域的挑战。
AI图像生成

RF Inversion
RF-Inversion是一个专注于图像生成和编辑的技术,它通过随机微分方程(SDE)来实现图像的反转和编辑。这项技术的主要优点在于它不需要额外的训练、潜在优化、提示调整或复杂的注意力处理器,即可实现高效的图像反转和编辑。RF-Inversion在零样本反转和编辑方面表现出色,超越了以往的工作,在笔画到图像合成和语义图像编辑方面,通过大规模人类评估确认了用户偏好。该技术背景信息显示,它由德克萨斯大学奥斯汀分校和谷歌的研究人员共同开发,得到了NSF资助和其他研究合作奖的支持。
AI图像生成

Animate X
Animate-X是一个基于LDM的通用动画框架,用于各种角色类型(统称为X),包括人物拟态角色。该框架通过引入姿势指示器来增强运动表示,可以更全面地从驱动视频中捕获运动模式。Animate-X的主要优点包括对运动的深入建模,能够理解驱动视频的运动模式,并将其灵活地应用到目标角色上。此外,Animate-X还引入了一个新的Animated Anthropomorphic Benchmark (A2Bench) 来评估其在通用和广泛适用的动画图像上的性能。
AI图像生成

Video Background Removal
Video Background Removal 是一个由 innova-ai 提供的 Hugging Face Space,专注于视频背景移除技术。该技术通过深度学习模型,能够自动识别并分离视频中的前景和背景,实现一键去除视频背景的功能。这项技术在视频制作、在线教育、远程会议等多个领域都有广泛的应用,尤其在需要抠图或更换视频背景的场景下,提供了极大的便利。产品背景信息显示,该技术是基于开源社区 Hugging Face 的 Spaces 平台开发的,继承了开源、共享的技术理念。目前,产品提供免费试用,具体价格信息需进一步查询。
AI视频编辑

Meissonic
Meissonic是一个非自回归的掩码图像建模文本到图像合成模型,能够生成高分辨率的图像。它被设计为可以在消费级显卡上运行。这项技术的重要性在于其能够利用现有的硬件资源,为用户带来高质量的图像生成体验,同时保持了较高的运行效率。Meissonic的背景信息包括其在arXiv上发表的论文,以及在Hugging Face上的模型和代码。
AI图像生成
替代品
国外精选

Gstory
GStory是一个在线视频和图片编辑平台,提供多种智能编辑功能,如背景更换、增强器、水印去除和AI图像生成器。它通过AI技术简化商业视频编辑流程,提高效率,降低成本,并被超过50,000家不同规模的公司所信赖。
AI视频编辑
Hallo2
Hallo2是一种基于潜在扩散生成模型的人像图像动画技术,通过音频驱动生成高分辨率、长时的视频。它通过引入多项设计改进,扩展了Hallo的功能,包括生成长时视频、4K分辨率视频,并增加了通过文本提示增强表情控制的能力。Hallo2的主要优点包括高分辨率输出、长时间的稳定性以及通过文本提示增强的控制性,这使得它在生成丰富多样的肖像动画内容方面具有显著优势。
AI图像生成

Talking Avatar
Talking Avatar是一款利用人工智能技术,允许用户通过编辑文本来更新旁白,无需重新录制,即可改变声音,包括口音、语调和情感。它支持一键多人唇形同步,确保视频观看体验自然而沉浸。此外,它还支持一句话声音克隆技术,用户只需提供一句话的音频样本,即可克隆任何声音,并用于生成任何语音。这款产品对于视频创作者、广告代理商、市场营销人员和教育工作者等都是一个强大的工具,可以轻松地将经典视频片段转化为新的热门内容,或者为不同平台优化视频内容。
AI视频编辑

AI Sketchnotes Generator
AI Sketchnotes Generator是一款在线工具,能够将文本内容自动转换成吸引人的草图笔记。它特别适合专业人士、教育工作者和创意工作者使用。这个工具提供了多种草图笔记模板和示例,非常适合用于头脑风暴和演示。它利用先进的AI技术,帮助用户高效生成草图笔记,并支持将笔记导出为PNG、SVG、PDF格式。这个工具的背景是帮助用户以更直观、更有创意的方式呈现信息,提高学习效率和工作效率。
AI图像生成

Flux AI Img
Flux AI是一个利用先进AI算法来生成高质量图像的平台。它通过深度学习模型,能够在几秒钟内将用户的想法转化为视觉杰作。该平台提供实时生成、自定义输出、多语言支持、伦理AI和无缝集成等特点,旨在帮助用户快速实现创意,提高工作效率。Flux AI的背景信息显示,它致力于负责任的AI开发,尊重版权,避免偏见,并促进积极的社会影响。
AI图像生成
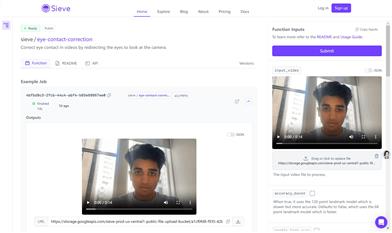
Sieve Eye Contact Correction
Sieve Eye Contact Correction API 是一个为开发者设计的快速且高质量的视频眼神校正API。该技术通过重定向眼神,确保视频中的人物即使没有直接看向摄像头,也能模拟出与摄像头进行眼神交流的效果。它支持多种自定义选项来微调眼神重定向,保留了原始的眨眼和头部动作,并通过随机的“看向别处”功能来避免眼神呆板。此外,还提供了分屏视图和可视化选项,以便于调试和分析。该API主要面向视频制作者、在线教育提供者和任何需要提升视频交流质量的用户。定价为每分钟视频0.10美元。
AI视频编辑
Comfygen
ComfyGen 是一个专注于文本到图像生成的自适应工作流系统,它通过学习用户提示来自动化并定制有效的工作流。这项技术的出现,标志着从使用单一模型到结合多个专业组件的复杂工作流的转变,旨在提高图像生成的质量。ComfyGen 背后的主要优点是能够根据用户的文本提示自动调整工作流,以生成更高质量的图像,这对于需要生成特定风格或主题图像的用户来说非常重要。
AI图像生成
中文精选

薯图宝
薯图宝是一款旨在提升图文制作效率的批量生成工具,它通过个性化模板和文案数据组合,快速生成大量图片,适用于小红书、抖音、视频号等全平台图文制作。产品背景信息显示,薯图宝能够极大提升生产效率,降低成本,特别适合需要大量图文内容的企业或个人使用。价格方面,提供年卡和永久两种套餐,满足不同用户的需求。
AI图像生成

Animegen
AnimeGen是一个利用先进AI模型将文本提示转化为动漫风格图片的在线工具。它通过复杂的算法和机器学习技术,为用户提供了一种简单快捷的方式来生成高质量的动漫图片,非常适合艺术家、内容创作者和动漫爱好者探索新的创作可能性。AnimeGen支持80多种语言,生成的图片公开显示并可被搜索引擎抓取,是一个多功能的创意工具。
AI图像生成