%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Blip 3o
Blip 3o 是一個基於 Hugging Face 平臺的應用程序,利用先進的生成模型從文本生成圖像,或對現有圖像進行分析和回答。該產品為用戶提供了強大的圖像生成和理解能力,非常適合設計師、藝術家和開發者。此技術的主要優點是其高效的圖像生成速度和優質的生成效果,同時還支持多種輸入形式,增強了用戶體驗。該產品是免費的,定位於開放給廣大用戶使用。
圖片生成
47.2K
Cogview4 6B
CogView4-6B 是由清華大學知識工程組開發的文本到圖像生成模型。它基於深度學習技術,能夠根據用戶輸入的文本描述生成高質量的圖像。該模型在多個基準測試中表現優異,尤其是在中文文本生成圖像方面具有顯著優勢。其主要優點包括高分辨率圖像生成、支持多種語言輸入以及高效的推理速度。該模型適用於創意設計、圖像生成等領域,能夠幫助用戶快速將文字描述轉化為視覺內容。
圖片生成
91.6K
優質新品
Cogview4
CogView4 是由清華大學開發的先進文本到圖像生成模型,基於擴散模型技術,能夠根據文本描述生成高質量圖像。它支持中文和英文輸入,並且可以生成高分辨率圖像。CogView4 的主要優點是其強大的多語言支持和高質量的圖像生成能力,適合需要高效生成圖像的用戶。該模型在 ECCV 2024 上展示,具有重要的研究和應用價值。
圖片生成
82.8K

Diffsplat
DiffSplat 是一種創新的 3D 生成技術,能夠從文本提示和單視圖圖像快速生成 3D 高斯點雲。該技術通過利用大規模預訓練的文本到圖像擴散模型,實現了高效的 3D 內容生成。它解決了傳統 3D 生成方法中數據集有限和無法有效利用 2D 預訓練模型的問題,同時保持了 3D 一致性。DiffSplat 的主要優點包括高效的生成速度(1~2 秒內完成)、高質量的 3D 輸出以及對多種輸入條件的支持。該模型在學術研究和工業應用中具有廣泛前景,尤其是在需要快速生成高質量 3D 模型的場景中。
3D建模
51.9K
Fashion Hut Modeling LoRA
Fashion-Hut-Modeling-LoRA是一個基於Diffusion技術的文本到圖像生成模型,主要用於生成時尚模特的高質量圖像。該模型通過特定的訓練參數和數據集,能夠根據文本提示生成具有特定風格和細節的時尚攝影圖像。它在時尚設計、廣告製作等領域具有重要應用價值,能夠幫助設計師和廣告商快速生成創意概念圖。模型目前仍在訓練階段,可能存在一些生成效果不佳的情況,但已經展示了強大的潛力。該模型的訓練數據集包含14張高分辨率圖像,使用了AdamW優化器和constant學習率調度器等參數,訓練過程注重圖像的細節和質量。
圖片生成
81.7K
Flux Midjourney Mix2 LoRA
Flux-Midjourney-Mix2-LoRA 是一款基於深度學習的文本到圖像生成模型,旨在通過自然語言描述生成高質量的圖像。該模型基於Diffusion架構,結合了LoRA技術,能夠實現高效的微調和風格化圖像生成。其主要優點包括高分辨率輸出、多樣化的風格支持以及對複雜場景的出色表現能力。該模型適用於需要高質量圖像生成的用戶,如設計師、藝術家和內容創作者,能夠幫助他們快速實現創意構思。
圖片生成
64.6K

Neuralsvg
NeuralSVG是一種用於從文本提示生成矢量圖形的隱式神經表示方法。它受到神經輻射場(NeRFs)的啟發,將整個場景編碼到一個小的多層感知器(MLP)網絡的權重中,並使用分數蒸餾採樣(SDS)進行優化。該方法通過引入基於dropout的正則化技術,鼓勵生成的SVG具有分層結構,使每個形狀在整體場景中具有獨立的意義。此外,其神經表示還提供了推理時控制的優勢,允許用戶根據提供的輸入動態調整生成的SVG,如顏色、寬高比等,且只需一個學習到的表示。通過廣泛的定性和定量評估,NeuralSVG在生成結構化和靈活的SVG方面優於現有方法。該模型由特拉維夫大學和MIT CSAIL的研究人員共同開發,目前代碼尚未公開。
AI設計工具
50.2K
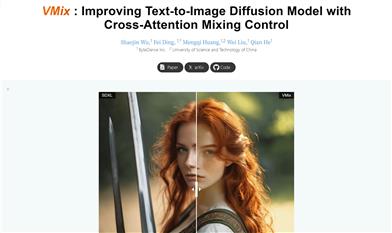
Vmix
VMix是一種用於提升文本到圖像擴散模型美學質量的技術,通過創新的條件控制方法——價值混合交叉注意力,系統性地增強圖像的美學表現。VMix作為一個即插即用的美學適配器,能夠在保持視覺概念通用性的同時提升生成圖像的質量。VMix的關鍵洞見是通過設計一種優越的條件控制方法來增強現有擴散模型的美學表現,同時保持圖像與文本的對齊。VMix足夠靈活,可以應用於社區模型,以實現更好的視覺性能,無需重新訓練。
圖片生成
49.4K
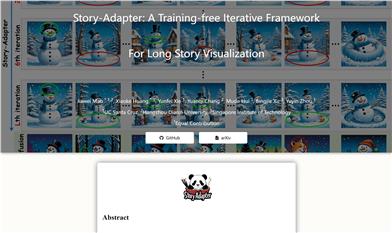
Story Adapter
Story-Adapter是一個無需訓練的迭代框架,專為長篇故事可視化設計。它通過迭代範式和全局參考交叉注意力模塊,優化圖像生成過程,保持故事中語義的連貫性,同時減少計算成本。該技術的重要性在於它能夠在長篇故事中生成高質量、細節豐富的圖像,解決了傳統文本到圖像模型在長故事可視化中的挑戰,如語義一致性和計算可行性。
圖片生成
108.7K

Dynamiccontrol
DynamicControl是一個用於提升文本到圖像擴散模型控制力的框架。它通過動態組合多樣的控制信號,支持自適應選擇不同數量和類型的條件,以更可靠和詳細地合成圖像。該框架首先使用雙循環控制器,利用預訓練的條件生成模型和判別模型,為所有輸入條件生成初始真實分數排序。然後,通過多模態大型語言模型(MLLM)構建高效條件評估器,優化條件排序。DynamicControl聯合優化MLLM和擴散模型,利用MLLM的推理能力促進多條件文本到圖像任務,最終排序的條件輸入到並行多控制適配器,學習動態視覺條件的特徵圖並整合它們以調節ControlNet,增強對生成圖像的控制。
AI模型
45.8K
Luminabrush
LuminaBrush是一個交互式工具,旨在繪製圖像上的照明效果。該工具採用兩階段方法:一階段將圖像轉換為“均勻照明”的外觀,另一階段根據用戶塗鴉生成照明效果。這種分解方法簡化了學習過程,避免了單一階段可能需要考慮的外部約束(如光傳輸一致性等)。LuminaBrush利用從高質量野外圖像中提取的“均勻照明”外觀來構建訓練最終交互式照明繪圖模型的配對數據。此外,該工具還可以獨立使用“均勻照明階段”來“去照明”圖像。
AI設計工具
52.2K
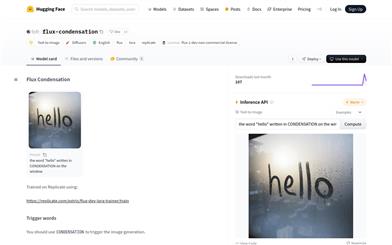
Flux Condensation
fofr/flux-condensation是一個基於文本生成圖像的AI模型,使用Diffusers庫和LoRAs技術,能夠根據用戶提供的文本提示生成相應的圖像。該模型在Replicate上訓練,具有非商業性質的flux-1-dev許可證。它代表了文本到圖像生成技術的最新進展,能夠為設計師、藝術家和內容創作者提供強大的視覺表現工具。
圖片生成
60.2K
Sana 600M 512px
Sana是一個由NVIDIA開發的文本到圖像的生成框架,能夠高效生成高達4096×4096分辨率的圖像。Sana以其快速的速度和強大的文本圖像對齊能力,可以在筆記本電腦GPU上部署,代表了圖像生成技術的一個重要進步。該模型基於線性擴散變換器,使用預訓練的文本編碼器和空間壓縮的潛在特徵編碼器,能夠根據文本提示生成和修改圖像。Sana的開源代碼可在GitHub上找到,其研究和應用前景廣闊,尤其在藝術創作、教育工具和模型研究等方面。
圖片生成
66.8K
Grok Aurora
Aurora是Grok推出的新一代自迴歸圖像生成模型,它通過訓練數十億的互聯網樣本,具備了深刻的世界理解能力。Aurora擅長於照片級真實感渲染和精確遵循文本指令,支持多模態輸入,能夠從用戶提供的圖像中獲取靈感或直接編輯用戶圖像。Aurora的新功能在𝕏平臺上的選定國家已經可用,並將在一週內向所有用戶推出。
圖片生成
47.5K
Sana 600M 1024px
Sana是一個由NVIDIA開發的文本到圖像生成框架,能夠高效生成高達4096×4096分辨率的圖像。Sana以其快速的速度和強大的文本圖像對齊能力,使得在筆記本電腦GPU上也能部署。它是一個基於線性擴散變換器(text-to-image generative model)的模型,擁有1648M參數,專門用於生成1024px基礎的多尺度高寬圖像。Sana模型的主要優點包括高分辨率圖像生成、快速的合成速度以及強大的文本圖像對齊能力。Sana模型的背景信息顯示,它是基於開源代碼開發的,可以在GitHub上找到源代碼,同時它也遵循特定的許可證(CC BY-NC-SA 4.0 License)。
圖片生成
50.0K
Shou Xin
shou_xin是一個基於文本到圖像的生成模型,它能夠根據用戶提供的文本提示生成具有手訫風格的鉛筆素描圖像。這個模型使用了diffusers庫和lora技術,以實現高質量的圖像生成。shou_xin模型以其獨特的藝術風格和高效的圖像生成能力在圖像生成領域佔有一席之地,特別適合需要快速生成具有特定藝術風格的圖像的用戶。
圖片生成
80.6K
Sana 1600M 1024px MultiLing
Sana是一個由NVIDIA開發的文本到圖像的框架,能夠高效生成高達4096×4096分辨率的圖像。該模型以驚人的速度合成高分辨率、高質量的圖像,並保持強大的文本-圖像對齊能力,可部署在筆記本電腦GPU上。Sana模型基於線性擴散變換器,使用預訓練的文本編碼器和空間壓縮的潛在特徵編碼器,支持Emoji、中文和英文以及混合提示。
圖片生成
51.3K
Bylo.ai
Bylo.ai是一款高級的AI圖像生成器,能夠將文本描述快速轉換為高質量的圖像。它支持負面提示和多種模型,包括流行的Flux AI圖像生成器,讓用戶可以自定義創作。Bylo.ai以其免費在線訪問、快速高效生成、高級自定義選項、靈活的圖像設置和高質量圖像輸出等特點,成為個人和商業用途的理想選擇。
圖片生成
87.8K
Awportraitcn
AWPortraitCN是一個基於FLUX.1-dev開發的文本到圖像生成模型,專門針對中國人的外貌和審美進行訓練。它包含多種類型的肖像,如室內外肖像、時尚和攝影棚照片,具有強大的泛化能力。與原始版本相比,AWPortraitCN在皮膚質感上更加細膩和真實。為了追求更真實的原始圖像效果,可以與AWPortraitSR工作流程一起使用。
圖片生成
54.6K
Sana 1600M 512px MultiLing
Sana是一個由NVIDIA開發的文本到圖像的框架,能夠高效生成高達4096×4096分辨率的圖像。Sana能夠以極快的速度合成高分辨率、高質量的圖像,並且具有強烈的文本-圖像對齊能力,可以在筆記本電腦GPU上部署。該模型基於線性擴散變換器,使用固定預訓練的文本編碼器和空間壓縮的潛在特徵編碼器,支持英文、中文和表情符號混合提示。Sana的主要優點包括高效率、高分辨率圖像生成能力以及多語言支持。
圖片生成
43.9K
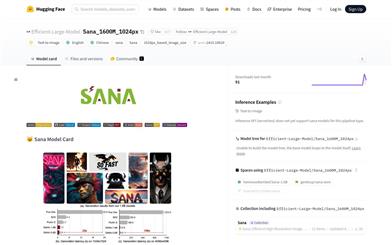
Sana 1600M 1024px
Sana是一個由NVIDIA開發的文本到圖像生成框架,能夠高效生成高達4096×4096分辨率的高清晰度、高文本-圖像一致性的圖像,並且速度極快,可以在筆記本電腦GPU上部署。Sana模型基於線性擴散變換器,使用預訓練的文本編碼器和空間壓縮的潛在特徵編碼器。該技術的重要性在於其能夠快速生成高質量的圖像,對於藝術創作、設計和其他創意領域具有革命性的影響。Sana模型遵循CC BY-NC-SA 4.0許可協議,源代碼可在GitHub上找到。
圖片生成
48.9K
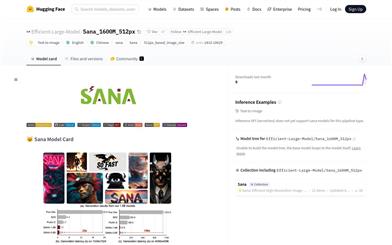
Sana 1600M 512px
Sana是一個由NVIDIA開發的文本到圖像的生成框架,能夠高效生成高達4096×4096分辨率的圖像。Sana以其快速的速度、強大的文本圖像對齊能力以及可在筆記本電腦GPU上部署的特性而著稱。該模型基於線性擴散變換器,使用預訓練的文本編碼器和空間壓縮的潛在特徵編碼器,代表了文本到圖像生成技術的最新進展。Sana的主要優點包括高分辨率圖像生成、快速合成、筆記本電腦GPU上的可部署性,以及開源的代碼,使其在研究和實際應用中具有重要價值。
圖片生成
48.9K
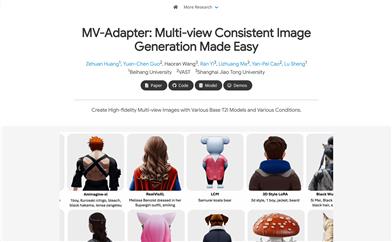
MV Adapter
MV-Adapter是一種基於適配器的多視圖圖像生成解決方案,它能夠在不改變原有網絡結構或特徵空間的前提下,增強預訓練的文本到圖像(T2I)模型及其衍生模型。通過更新更少的參數,MV-Adapter實現了高效的訓練並保留了預訓練模型中嵌入的先驗知識,降低了過擬合風險。該技術通過創新的設計,如複製的自注意力層和並行注意力架構,使得適配器能夠繼承預訓練模型的強大先驗,以建模新的3D知識。此外,MV-Adapter還提供了統一的條件編碼器,無縫整合相機參數和幾何信息,支持基於文本和圖像的3D生成以及紋理映射等應用。MV-Adapter在Stable Diffusion XL(SDXL)上實現了768分辨率的多視圖生成,並展示了其適應性和多功能性,能夠擴展到任意視圖生成,開啟更廣泛的應用可能性。
圖片生成
71.2K
Text To Pose
text-to-pose是一個研究項目,旨在通過文本描述生成人物姿態,並利用這些姿態生成圖像。該技術結合了自然語言處理和計算機視覺,通過改進擴散模型的控制和質量,實現了從文本到圖像的生成。項目背景基於NeurIPS 2024 Workshop上發表的論文,具有創新性和前沿性。該技術的主要優點包括提高圖像生成的準確性和可控性,以及在藝術創作和虛擬現實等領域的應用潛力。
圖片生成
53.3K

Sana
Sana是一個文本到圖像的框架,能夠高效生成高達4096×4096分辨率的圖像。它以極快的速度合成高分辨率、高質量的圖像,並保持強大的文本-圖像對齊,可以部署在筆記本電腦GPU上。Sana的核心設計包括深度壓縮自編碼器、線性擴散變換器(DiT)、僅解碼器的小型語言模型作為文本編碼器,以及高效的訓練和採樣策略。Sana-0.6B與現代大型擴散模型相比,體積小20倍,測量吞吐量快100倍以上。此外,Sana-0.6B可以部署在16GB筆記本電腦GPU上,生成1024×1024分辨率圖像的時間少於1秒。Sana使得低成本的內容創作成為可能。
圖片生成
55.2K
Stable Diffusion 3.5 ControlNets
Stable Diffusion 3.5 ControlNets是由Stability AI提供的文本到圖像的AI模型,支持多種控制網絡(ControlNets),如Canny邊緣檢測、深度圖和高保真上採樣等。該模型能夠根據文本提示生成高質量的圖像,特別適用於插畫、建築渲染和3D資產紋理等場景。它的重要性在於能夠提供更精細的圖像控制能力,提升生成圖像的質量和細節。產品背景信息包括其在學術界的引用(arxiv:2302.05543),以及遵循的Stability Community License。價格方面,對於非商業用途、年收入不超過100萬美元的商業用途免費,超過則需聯繫企業許可。
圖片生成
49.1K
FLUX.1 Dev IP Adapter
FLUX.1-dev-IP-Adapter是一個基於FLUX.1-dev模型的IP-Adapter,由InstantX Team研發。該模型能夠將圖像工作處理得像文本一樣靈活,使得圖像生成和編輯更加高效和直觀。它支持圖像參考,但不適用於細粒度的風格轉換或角色一致性。模型在10M開源數據集上訓練,使用128的批量大小和80K的訓練步驟。該模型在圖像生成領域具有創新性,能夠提供多樣化的圖像生成解決方案,但可能存在風格或概念覆蓋不足的問題。
文本到圖像
66.8K
國外精選
FLUX.1 Tools
FLUX.1 Tools是Black Forest Labs推出的一套模型工具,旨在為基於文本的圖像生成模型FLUX.1增加控制和可操作性,使得對真實和生成的圖像進行修改和再創造成為可能。該工具套件包含四個不同的特性,以開放訪問模型的形式在FLUX.1 [dev]模型系列中提供,並作為BFL API的補充,支持FLUX.1 [pro]。FLUX.1 Tools的主要優點包括先進的圖像修復和擴展能力、結構化引導、圖像變化和重構等,這些功能對於圖像編輯和創作領域具有重要意義。
文本到圖像
72.3K
Edify Image
Edify Image是NVIDIA推出的一款圖像生成模型,它能夠生成具有像素級精確度的逼真圖像內容。該模型採用級聯像素空間擴散模型,並通過新穎的拉普拉斯擴散過程進行訓練,該過程能夠在不同頻率帶以不同的速率衰減圖像信號。Edify Image支持多種應用,包括文本到圖像合成、4K上採樣、ControlNets、360° HDR全景圖生成和圖像定製微調。它代表了圖像生成技術的最新進展,具有廣泛的應用前景和重要的商業價值。
圖片生成
53.8K
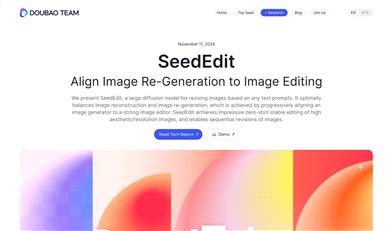
Seededit
SeedEdit是Doubao Team推出的大型擴散模型,用於根據任何文本提示修訂圖像。它通過逐步將圖像生成器與強大的圖像編輯器對齊,實現了圖像重建和圖像再生之間的最佳平衡。SeedEdit能夠實現高審美/分辨率圖像的零樣本穩定編輯,並支持圖像的連續修訂。該技術的重要性在於其能夠解決圖像編輯問題中成對圖像數據稀缺的核心難題,通過將文本到圖像(T2I)生成模型視為弱編輯模型,並通過生成帶有新提示的新圖像來實現“編輯”,然後將其蒸餾並與之對齊到圖像條件編輯模型中。
圖片編輯
231.3K
- 1
- 2
- 3
- 4
- 5
精選AI產品推薦
中文精選

騰訊混元圖像 2.0
騰訊混元圖像 2.0 是騰訊最新發布的 AI 圖像生成模型,顯著提升了生成速度和畫質。通過超高壓縮倍率的編解碼器和全新擴散架構,使得圖像生成速度可達到毫秒級,避免了傳統生成的等待時間。同時,模型通過強化學習算法與人類美學知識的結合,提升了圖像的真實感和細節表現,適合設計師、創作者等專業用戶使用。
圖片生成
80.6K
國外精選

Lovart
Lovart 是一款革命性的 AI 設計代理,能夠將創意提示轉化為藝術作品,支持從故事板到品牌視覺的多種設計需求。其重要性在於打破傳統設計流程,節省時間並提升創意靈感。Lovart 當前處於測試階段,用戶可加入等候名單,隨時體驗設計的樂趣。
AI設計工具
63.8K

Fastvlm
FastVLM 是一種高效的視覺編碼模型,專為視覺語言模型設計。它通過創新的 FastViTHD 混合視覺編碼器,減少了高分辨率圖像的編碼時間和輸出的 token 數量,使得模型在速度和精度上表現出色。FastVLM 的主要定位是為開發者提供強大的視覺語言處理能力,適用於各種應用場景,尤其在需要快速響應的移動設備上表現優異。
AI模型
51.1K

Keysync
KeySync 是一個針對高分辨率視頻的無洩漏唇同步框架。它解決了傳統唇同步技術中的時間一致性問題,同時通過巧妙的遮罩策略處理表情洩漏和麵部遮擋。KeySync 的優越性體現在其在唇重建和跨同步方面的先進成果,適用於自動配音等實際應用場景。
視頻編輯
48.3K
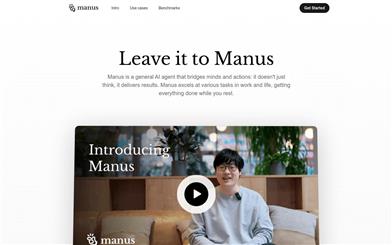
Manus
Manus 是由 Monica.im 研發的全球首款真正自主的 AI 代理產品,能夠直接交付完整的任務成果,而不僅僅是提供建議或答案。它採用 Multiple Agent 架構,運行在獨立虛擬機中,能夠通過編寫和執行代碼、瀏覽網頁、操作應用等方式直接完成任務。Manus 在 GAIA 基準測試中取得了 SOTA 表現,展現了強大的任務執行能力。其目標是成為用戶在數字世界的‘代理人’,幫助用戶高效完成各種複雜任務。
個人助理
1.5M
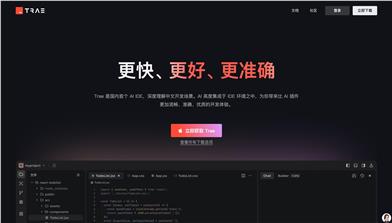
Trae國內版
Trae是一款專為中文開發場景設計的AI原生IDE,將AI技術深度集成於開發環境中。它通過智能代碼補全、上下文理解等功能,顯著提升開發效率和代碼質量。Trae的出現填補了國內AI集成開發工具的空白,滿足了中文開發者對高效開發工具的需求。其定位為高端開發工具,旨在為專業開發者提供強大的技術支持,目前尚未明確公開價格,但預計會採用付費模式以匹配其高端定位。
開發與工具
137.7K
國外精選

Pika
Pika是一個視頻製作平臺,用戶可以上傳自己的創意想法,Pika會自動生成相關的視頻。主要功能有:支持多種創意想法轉視頻,視頻效果專業,操作簡單易用。平臺採用免費試用模式,定位面向創意者和視頻愛好者。
視頻生成
18.7M
中文精選

Liblibai
LiblibAI是一箇中國領先的AI創作平臺,提供強大的AI創作能力,幫助創作者實現創意。平臺提供海量免費AI創作模型,用戶可以搜索使用模型進行圖像、文字、音頻等創作。平臺還支持用戶訓練自己的AI模型。平臺定位於廣大創作者用戶,致力於創造條件普惠,服務創意產業,讓每個人都享有創作的樂趣。
AI模型
8.0M