%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
RF DETR
RF-DETR 是一個基於變壓器的即時目標檢測模型,旨在為邊緣設備提供高精度和即時性能。它在 Microsoft COCO 基準測試中超過了 60 AP,具有競爭力的性能和快速的推理速度,適合各種實際應用場景。RF-DETR 旨在解決現實世界中的物體檢測問題,適用於需要高效且準確檢測的行業,如安防、自動駕駛和智能監控等。
目標檢測
141.9K
Agentic Object Detection
Agentic Object Detection 是一種先進的推理驅動目標檢測技術,能夠通過文本提示精確識別圖像中的目標對象。它無需大量的自定義訓練數據,即可實現類似人類精度的檢測。該技術利用設計模式對目標的獨特屬性(如顏色、形狀和紋理)進行深度推理,從而在各種場景中實現更智能、更精確的識別。其主要優點包括高精度、無需大量訓練數據以及能夠處理複雜場景。該技術適用於需要高精度圖像識別的行業,如製造業、農業、醫療等領域,能夠幫助企業提高生產效率和質量控制水平。產品目前處於試用階段,用戶可以免費試用體驗其功能。
AI模型
63.8K
中文精選
DINO X
DINO-X是一個以物體感知為核心的視覺大模型,具備開集檢測、智能問答、人體姿態、物體計數、服裝換色等核心能力。它不僅能識別已知目標,還能靈活應對未知類別,憑藉先進算法,模型具備出色的適應性和魯棒性,能夠精準應對各種不可預見的挑戰,提供針對複雜視覺數據的全方位解決方案。DINO-X的應用場景廣泛,包括機器人、農業、零售行業、安防監控、交通管理、製造業、智能家居、物流與倉儲、娛樂媒體等,是DeepDataSpace公司在計算機視覺技術領域的旗艦產品。
目標檢測
78.1K
D FINE
D-FINE是一個強大的即時目標檢測模型,它通過將DETRs中的邊界框迴歸任務重新定義為細粒度分佈細化(FDR),並引入全局最優定位自蒸餾(GO-LSD),在不增加額外推理和訓練成本的情況下,實現了出色的性能。該模型由中國科學院的研究人員開發,旨在提高目標檢測的精度和效率。
模型訓練與部署
53.8K

YOLO11
Ultralytics YOLO11是基於之前YOLO系列模型的進一步發展,引入了新特性和改進,以提高性能和靈活性。YOLO11旨在快速、準確、易於使用,非常適合廣泛的目標檢測、跟蹤、實例分割、圖像分類和姿態估計任務。
AI圖像檢測識別
66.2K
Florence 2 Large
Florence-2-large是由微軟開發的先進視覺基礎模型,採用基於提示的方法處理廣泛的視覺和視覺-語言任務。該模型能夠解釋簡單的文本提示來執行如圖像描述、目標檢測和分割等任務。它利用包含54億註釋的5.4億圖像的FLD-5B數據集,精通多任務學習。其序列到序列的架構使其在零樣本和微調設置中均表現出色,證明是一個有競爭力的視覺基礎模型。
AI圖像生成
55.8K
Yolov10:
YOLOv10是新一代的目標檢測模型,它在保持即時性能的同時,實現了高精度的目標檢測。該模型通過優化後處理和模型架構,減少了計算冗餘,提高了效率和性能。YOLOv10在不同模型規模上都達到了最先進的性能和效率,例如,YOLOv10-S在相似的AP下比RT-DETR-R18快1.8倍,同時參數數量和FLOPs減少了2.8倍。
AI模型
79.8K
Grounding DINO 1.5 API
Grounding DINO 1.5是由IDEA Research開發,旨在推進開放世界目標檢測技術邊界的高級模型系列。該系列包含兩個模型:Grounding DINO 1.5 Pro和Grounding DINO 1.5 Edge,分別針對廣泛的應用場景和邊緣計算場景進行了優化。
AI圖像檢測識別
82.5K
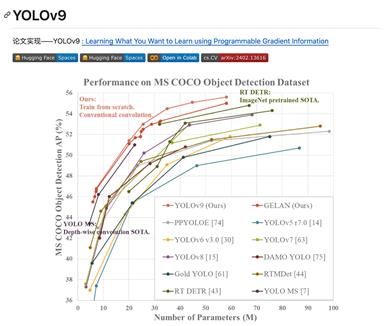
Yolov9
yolov9是YOLOv9論文的實現,它通過使用可編程梯度信息來學習用戶想要學習的內容。這個項目是一個開源的深度學習模型,主要用於目標檢測任務,具有高效和準確的優勢。
AI圖像檢測識別
163.4K

Yolov8
YOLOv8是YOLO系列目標檢測模型的最新版本,能夠在圖像或視頻中準確快速地識別和定位多個對象,並即時跟蹤它們的移動。相比之前版本,YOLOv8在檢測速度和精確度上都有很大提升,同時支持多種額外的計算機視覺任務,如實例分割、姿態估計等。YOLOv8可通過多種格式部署在不同硬件平臺上,提供一站式的端到端目標檢測解決方案。
AI圖像檢測識別
269.7K
PIXTA AI AI/ML Training Data Service
Pixta AI是一家提供大規模數據標註和數據採集解決方案的公司。我們擁有1000多名經驗豐富的標註員,超過9000萬張圖片和1000萬個視頻。通過我們的服務,可以加速您的AI開發。我們提供的標註和數據採集服務能夠滿足各種需求,並且可以根據您的項目進行定製化。
數據分析
47.7K

Lobe
Lobe是一個免費、易於使用的工具,幫助您訓練自定義的機器學習模型,並在您的應用程序中使用。Lobe具備一切您需要將機器學習想法實現的功能。只需展示給它您想讓它學習的示例,它就會自動訓練一個定製的機器學習模型,可在您的應用程序中使用。
模型訓練與部署
53.0K
精選AI產品推薦
中文精選

騰訊混元圖像 2.0
騰訊混元圖像 2.0 是騰訊最新發布的 AI 圖像生成模型,顯著提升了生成速度和畫質。通過超高壓縮倍率的編解碼器和全新擴散架構,使得圖像生成速度可達到毫秒級,避免了傳統生成的等待時間。同時,模型通過強化學習算法與人類美學知識的結合,提升了圖像的真實感和細節表現,適合設計師、創作者等專業用戶使用。
圖片生成
81.4K
國外精選

Lovart
Lovart 是一款革命性的 AI 設計代理,能夠將創意提示轉化為藝術作品,支持從故事板到品牌視覺的多種設計需求。其重要性在於打破傳統設計流程,節省時間並提升創意靈感。Lovart 當前處於測試階段,用戶可加入等候名單,隨時體驗設計的樂趣。
AI設計工具
64.3K

Fastvlm
FastVLM 是一種高效的視覺編碼模型,專為視覺語言模型設計。它通過創新的 FastViTHD 混合視覺編碼器,減少了高分辨率圖像的編碼時間和輸出的 token 數量,使得模型在速度和精度上表現出色。FastVLM 的主要定位是為開發者提供強大的視覺語言處理能力,適用於各種應用場景,尤其在需要快速響應的移動設備上表現優異。
AI模型
51.3K

Keysync
KeySync 是一個針對高分辨率視頻的無洩漏唇同步框架。它解決了傳統唇同步技術中的時間一致性問題,同時通過巧妙的遮罩策略處理表情洩漏和麵部遮擋。KeySync 的優越性體現在其在唇重建和跨同步方面的先進成果,適用於自動配音等實際應用場景。
視頻編輯
48.6K
Manus
Manus 是由 Monica.im 研發的全球首款真正自主的 AI 代理產品,能夠直接交付完整的任務成果,而不僅僅是提供建議或答案。它採用 Multiple Agent 架構,運行在獨立虛擬機中,能夠通過編寫和執行代碼、瀏覽網頁、操作應用等方式直接完成任務。Manus 在 GAIA 基準測試中取得了 SOTA 表現,展現了強大的任務執行能力。其目標是成為用戶在數字世界的‘代理人’,幫助用戶高效完成各種複雜任務。
個人助理
1.5M
Trae國內版
Trae是一款專為中文開發場景設計的AI原生IDE,將AI技術深度集成於開發環境中。它通過智能代碼補全、上下文理解等功能,顯著提升開發效率和代碼質量。Trae的出現填補了國內AI集成開發工具的空白,滿足了中文開發者對高效開發工具的需求。其定位為高端開發工具,旨在為專業開發者提供強大的技術支持,目前尚未明確公開價格,但預計會採用付費模式以匹配其高端定位。
開發與工具
138.8K
國外精選

Pika
Pika是一個視頻製作平臺,用戶可以上傳自己的創意想法,Pika會自動生成相關的視頻。主要功能有:支持多種創意想法轉視頻,視頻效果專業,操作簡單易用。平臺採用免費試用模式,定位面向創意者和視頻愛好者。
視頻生成
18.7M
中文精選

Liblibai
LiblibAI是一箇中國領先的AI創作平臺,提供強大的AI創作能力,幫助創作者實現創意。平臺提供海量免費AI創作模型,用戶可以搜索使用模型進行圖像、文字、音頻等創作。平臺還支持用戶訓練自己的AI模型。平臺定位於廣大創作者用戶,致力於創造條件普惠,服務創意產業,讓每個人都享有創作的樂趣。
AI模型
8.0M