%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Video Processing

Memvid
Memvid is a revolutionary AI memory management solution that encodes text data into videos to enable fast semantic search across millions of text blocks. It is more efficient than traditional vector databases, with smaller storage requirements and the ability to quickly access information without a database. The product is free and positioned to enhance the efficiency of knowledge management and information retrieval.
Knowledge Management
48.9K

Keysync
KeySync is a leak-free lip-sync framework for high-resolution videos. It addresses the issue of temporal consistency in traditional lip-sync technologies while using a clever masking strategy to handle expression leakage and facial occlusion. KeySync excels in its advanced results in lip reconstruction and cross-synchronization, applicable to practical scenarios such as automatic dubbing.
Video Editing
49.4K
Bilive
bilive is a tool designed specifically for Bilibili live stream recording. It supports automatic segmentation, barrage rendering, and subtitle generation, is compatible with low-configuration devices, and is suitable for a wide range of users. Its main advantages lie in its efficient processing of live stream content, support for multi-room recording, and the ability to generate high-quality content and cover images, ensuring users can quickly share recording results. It is suitable for individuals and small teams. This product is open-source and free to use, committed to providing convenience for users.
Video Editing
50.8K

Describe Anything
The Describe Anything model (DAM) can process specific regions of images or videos and generate detailed descriptions. Its main advantage lies in its ability to generate high-quality localized descriptions through simple markings (points, boxes, scribbles, or masks), greatly enhancing image understanding capabilities in the field of computer vision. The model was jointly developed by NVIDIA and several universities and is suitable for research, development, and practical applications.
Image Generation
48.6K
AI Video And Audio To Text & Graphic Creator
The AI Video and Audio to Text & Graphic Creator is an open-source tool designed to convert video and audio content into various document formats, helping users to reread and reflect on the content. The main advantages of this product are that it is completely open-source, requires no registration, and users can process audio and video files locally, reducing the cost of use. It is ideal for students, researchers, and content creators who need to convert audio-visual content into text.
Video Editing
48.6K
Visionagent
VisionAgent is a powerful tool that utilizes artificial intelligence and large language models (LLMs) to generate code, helping users quickly solve vision tasks. Its primary advantage lies in its ability to automatically translate complex visual tasks into executable code, significantly improving development efficiency. VisionAgent supports various LLM providers, allowing users to choose models based on their specific needs. It is well-suited for developers and businesses requiring rapid development of visual applications, enabling them to implement robust visual solutions in a short timeframe. VisionAgent is currently free, aiming to provide users with efficient and convenient visual task processing capabilities.
Coding Assistant
60.7K
Fresh Picks
One Shot LoRA
One-Shot LoRA is an online platform focused on rapidly training LoRA models from videos. It leverages advanced machine learning technology to efficiently convert video content into LoRA models, providing users with a fast and convenient model generation service. The primary benefits of this product are its ease of use, no login requirement, and privacy protection. It does not require users to upload private data, nor does it store or collect any user information, ensuring the confidentiality and security of user data. This product is mainly aimed at users who need to quickly generate LoRA models, such as designers and developers, helping them quickly obtain the necessary model resources and improve work efficiency.
Model Training and Deployment
62.1K
Deeptrain
Deeptrain is a platform dedicated to video processing, designed to seamlessly integrate video content into language models and AI agents. With its powerful video processing technology, users can easily utilize video content just like text and images. The product supports over 200 language models, including GPT-4o and Gemini, and offers multilingual video processing. Deeptrain provides free development support, only charging for usage in a production environment, making it an ideal choice for AI application development. Key advantages include powerful video processing capabilities, multilingual support, and seamless integration with major language models.
Video Editing
57.1K
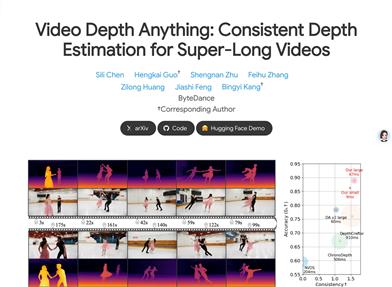
Video Depth Anything
Video Depth Anything is a deep learning-based video depth estimation model capable of providing high-quality and temporally consistent depth estimates for super-long videos. This technology is developed based on Depth Anything V2, boasting strong generalization capabilities and stability. Its primary advantages include the ability to estimate depth for any length of video, temporal consistency, and adaptability to open-world video. The model was developed by ByteDance's research team to address challenges in depth estimation for long videos, such as temporal consistency and adaptability in complex scenes. The code and demos for this model are currently available for researchers and developers.
Video Editing
62.7K
Zight
Zight AI is an intelligent tool focused on video content processing. Utilizing advanced natural language processing technology, it can quickly generate titles, summaries, subtitles, and multilingual translations for videos. Its main advantages include high levels of automation that significantly save users' time and effort while enhancing the accessibility and usability of video content. Zight AI is suitable for various scenarios, including corporate training, customer service, and education, aiming to boost productivity in video content creation through intelligent methods. The service is subscription-based, starting at $4 per user per month, making it ideal for individuals and teams seeking efficient video content processing.
Video Editing
58.8K

Stereocrafter
StereoCrafter is an innovative framework that employs foundational models as priors, utilizing depth estimation and stereo video reconstruction techniques to transform 2D videos into immersive stereo 3D experiences. This technology overcomes the limitations of traditional methods, enhancing the high-fidelity generation performance required by display devices. Key advantages of StereoCrafter include its ability to process video inputs of varying lengths and resolutions, as well as optimizing video processing through autoregressive strategies and chunk processing. Additionally, StereoCrafter has developed complex data processing workflows to reconstruct large-scale, high-quality datasets that support the training process. This framework provides practical solutions for creating immersive content for 3D devices such as Apple Vision Pro and 3D monitors, potentially revolutionizing how we experience digital media.
Video Production
67.9K
Fresh Picks
Vidtok
VidTok is a series of advanced video segmenters open-sourced by Microsoft, excelling in both temporal and spatial segmentation. It features significant innovations in architectural efficiency, quantization techniques, and training strategies, providing efficient video processing capabilities and outperforming previous models across multiple video quality assessment metrics. The development of VidTok aims to advance video processing and compression technologies, which are crucial for the efficient transmission and storage of video content.
Video Editing
53.5K
Endlessai
EndlessAI is a platform centered on AI video capabilities, currently operating in stealth mode. It offers demonstrations through the Lloyd mobile app available on the App Store, allowing users to experience the powerful features of AI video technology. The technical background of EndlessAI emphasizes its expertise in video processing and AI applications. Though pricing and specific positioning information are not explicitly stated on the page, it can be inferred that the main target audience is users who require high-end video processing and AI integration solutions.
Video Production
53.3K

Mmaudio
MMAudio is a multimodal joint training technology aimed at high-quality video-to-audio synthesis. This technology can generate synchronized audio from video and text inputs, suitable for various applications such as film production and game development. Its significance lies in improving the efficiency and quality of audio generation, making it ideal for creators and developers in need of audio synthesis.
Video Production
66.5K
Comfyui HunyuanVideoWrapper
ComfyUI-HunyuanVideoWrapper is a video processing interface based on HunyuanVideo, designed primarily for video encoding and decoding. It employs advanced video processing technology that allows users to handle videos on lower hardware requirements, even on devices with limited memory. This product is particularly well-suited for users needing to process video in resource-constrained environments, and it is open source, available for free use.
Video Editing
74.2K
AI FFmpeg
AI-FFmpeg is an online video processing tool that harnesses the power of FFmpeg, providing users with an easy-to-use interface for handling video files. This product supports multiple functionalities including video transcoding, compression, audio extraction, trimming, rotation, and basic effects adjustment, making it a powerful assistant for video editing and processing. With its free access, user-friendly design, and comprehensive features, AI-FFmpeg meets the needs of both amateur and professional video enthusiasts.
Video Editing
59.6K
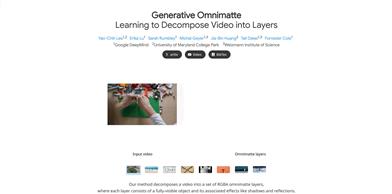
Generative Omnimatte
Generative Omnimatte is an advanced video processing technology that can decompose videos into multiple RGBA layers, with each layer capturing visible objects and their effects, such as shadows and reflections. This technology is significant in video editing and visual effects production, enhancing creative flexibility and efficiency.
Video Editing
48.3K
Comfyui GIMM VFI
ComfyUI-GIMM-VFI is a frame interpolation tool based on the GIMM-VFI algorithm, enabling users to achieve high-quality frame interpolation effects in image and video processing. This technology enhances the frame rate of videos by inserting new frames between consecutive ones, making actions appear smoother. This is particularly important for applications requiring high frame rate videos, such as video games and film post-production. Background information indicates that it is developed in Python and relies on the CuPy library, making it especially suitable for high-performance computing scenarios.
Video Editing
93.6K
Vidpanos
VidPanos is an innovative video processing technology that converts casual panning footage taken by users into panoramic videos. This technology generates a panoramic video of the same length as the original through space-time extrapolation. VidPanos utilizes generative video models to address the challenge of capturing dynamic scenes when moving objects are present, effectively handling various outdoor scenes including people, vehicles, flowing water, and static backgrounds, showcasing impressive practicality and innovation.
Video Editing
58.5K
Wav2lip
Wav2Lip is an open-source project aimed at achieving high synchronization between characters' lips and arbitrary target speech in videos using deep learning technology. The project provides complete training codes, inference codes, and pre-trained models, supporting any identity, voice, and language, including CGI faces and synthetic voices. The technology behind Wav2Lip is based on the paper 'A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild,' which was published at ACM Multimedia 2020. The project also features an interactive demo and a Google Colab notebook for users to quickly get started. Furthermore, the project offers new, reliable evaluation benchmarks and metrics, along with explanations on how to calculate these metrics from the paper.
Video Editing
76.5K
Sieve Eye Contact Correction
The Sieve Eye Contact Correction API is a fast and high-quality solution designed for developers, enabling eye contact correction in videos. This technology redirects eye gaze, allowing video subjects to simulate eye contact with the camera even when not directly facing it. It supports various customization options to fine-tune eye gaze redirection while preserving natural blinking and head movements, and introduces a random 'look away' feature to prevent a fixed gaze. Additionally, it offers split-screen views and visualization options for easy debugging and analysis. This API is primarily aimed at video creators, online education providers, and anyone looking to enhance video communication quality. The pricing is $0.10 per minute of video.
AI Video Editing
105.7K

Video Background Removal
Video Background Removal is a Hugging Face Space provided by innova-ai, focusing on video background removal technology. This technology leverages deep learning models to automatically identify and separate foreground and background in videos, enabling one-click background removal. Its applications span various fields including video production, online education, and remote meetings, offering significant convenience especially in scenarios requiring cutting or changing video backgrounds. The product is developed on the open-source community platform Hugging Face's Spaces, inheriting the principles of open source and sharing. Currently, a free trial is available, with detailed pricing information to be further inquired.
AI video editing
143.5K
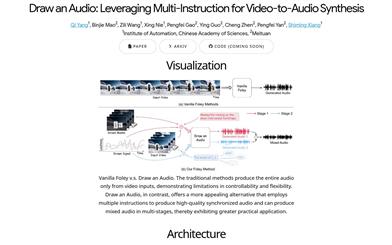
Draw An Audio
Draw an Audio is an innovative video-to-audio synthesis technology that generates high-quality synchronized audio based on video content through multi-command control. This technology not only enhances the controllability and flexibility of audio generation but also enables multi-stage mixed audio production, showcasing a broader range of practical applications.
AI audio editing
54.9K
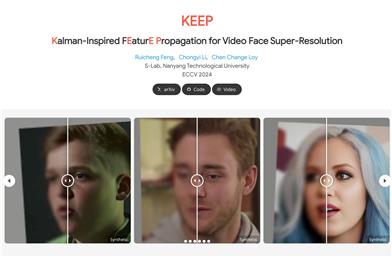
KEEP
KEEP is a video face super-resolution framework based on the principles of Kalman filtering, aimed at maintaining stable face priors over time through feature propagation. It effectively captures consistent facial details across video frames by integrating information from previously recovered frames to guide and adjust the recovery process of the current frame.
AI video enhancement
95.8K
Youdub Webui
YouDub-webui is a web-based interactive tool built on Gradio designed to translate and dub high-quality videos from YouTube and other platforms into Chinese. It combines AI technologies, including speech recognition, large language model translation, and AI voice cloning, providing a Chinese dubbing experience similar to the original video, thus enhancing the viewing experience for Chinese users.
AI video translation
74.0K
Comfyui CogVideoXWrapper
ComfyUI-CogVideoXWrapper is a Python-based video processing model that utilizes the T5 model for video content generation and transformation. The model supports a workflow for converting images to videos, showcasing interesting results during its experimental phase. It primarily targets professional users who need to create and edit video content, particularly those with specific needs in video generation and conversion.
AI video generation
69.6K
Minicpm V 2.6
MiniCPM-V 2.6 is a multimodal large language model based on 800 million parameters, demonstrating leading performance in single image understanding, multiple image understanding, and video comprehension across various domains. The model achieved an average score of 65.2 on multiple popular benchmarks such as OpenCompass, surpassing widely used proprietary models. It possesses robust OCR capabilities, supports multiple languages, and performs efficiently, enabling real-time video understanding on devices like the iPad.
AI Model
56.6K
English Picks
Free On Device AI Caption And Subtitle Generator
This is an AI-based online subtitle generator that allows users to upload video files through the browser and complete subtitle generation and video rendering on their local devices. Data is not sent to the server, ensuring user data privacy and security.
Video Editing
65.1K
Jockey
Jockey is a conversational video agent built on top of Twelve Labs API and LangGraph. It integrates the capabilities of existing Large Language Models (LLMs) with Twelve Labs' API, utilizing LangGraph for task allocation to distribute the workload of complex video workflows to appropriate base models. LLMs are used for logically planning execution steps and interacting with users, while video-related tasks are passed to the Twelve Labs API powered by Video Foundation Models (VFMs) for native video processing, eliminating the need for intermediary representations like pre-generated captions.
AI video editing
51.9K
Comfyui ProPainter Nodes
ComfyUI ProPainter Nodes is a video repair plugin based on the ProPainter framework. It uses flow propagation and spacetime transformers to achieve advanced video frame editing, ideal for seamless repair tasks. The plugin features a user-friendly interface and powerful functionalities designed to simplify the video repair process.
AI video editing
84.7K
- 1
- 2
Featured AI Tools
English Picks

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
50.0K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
45.5K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
43.3K
Chinese Picks

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
43.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
45.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
43.3K
English Picks

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
Chinese Picks

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M