%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Diffusion model
Diffusion As Shader
Diffusion as Shader (DaS) is an innovative video generation control model designed to achieve diverse control over video generation through a 3D perception diffusion process. This model utilizes 3D tracking videos as control inputs, supporting multiple video control tasks under a unified architecture, including mesh-to-video generation, camera control, motion transfer, and object manipulation. The main advantage of DaS lies in its 3D perception capabilities, significantly enhancing the temporal consistency of generated videos and demonstrating powerful control abilities with minimal data and short tuning times. Developed collaboratively by research teams from institutions like the Hong Kong University of Science and Technology, the model aims to advance video generation technology, providing more flexible and efficient solutions for fields such as filmmaking and virtual reality.
Video Production
59.6K

Dynamiccontrol
DynamicControl is a framework designed to enhance the control of text-to-image diffusion models. It dynamically combines various control signals and supports adaptive selection of different numbers and types of conditions to synthesize images more reliably and in detail. The framework first utilizes a dual-loop controller, employing pre-trained conditional generation and discriminator models to generate initial real score rankings for all input conditions. Then, a multimodal large language model (MLLM) constructs an efficient condition evaluator to optimize the condition ordering. DynamicControl jointly optimizes MLLM and the diffusion model, leveraging the inference capabilities of MLLM to facilitate multi-condition text-to-image tasks. The final ordered conditions are input into a parallel multi-control adapter to learn dynamic visual condition feature maps and integrate them to adjust ControlNet, enhancing control over the generated images.
AI Model
50.0K
Stable Diffusion 3.5 Large Turbo
Stable Diffusion 3.5 Large Turbo is a multi-modal diffusion transformer (MMDiT) model for text-to-image generation, employing Adversarial Diffusion Distillation (ADD) technology to enhance image quality, layout, understanding of complex prompts, and resource efficiency, with a particular focus on reducing inference steps. This model excels in image generation, capable of understanding and generating complex text prompts, making it suitable for various image generation scenarios. It is published on the Hugging Face platform under the Stability Community License, allowing for free use by researchers, non-commercial use, and organizations or individuals with annual revenue under $1 million.
Image Generation
72.9K
TCAN
TCAN is a novel human character animation framework based on diffusion models that maintains temporal consistency and generalizes well to unseen domains. The framework ensures that generated videos maintain the original image's appearance while adhering to the posture of the driving video and maintaining background consistency through unique modules such as the Appearance-Posture Adaptation Layer (APPA), temporal control networks, and posture-driven temperature maps.
AI video generation
100.2K
Hallo
Hallo, a portrait image animation technology developed by Fudan University, utilizes diffusion models to generate realistic and dynamic portrait animations. Unlike traditional methods relying on parametric models for intermediate facial representations, Hallo adopts an end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the alignment precision between audio input and visual output, including lip, facial expression, and pose movements. This technology offers adaptive control over facial expression and pose diversity, enabling more effective personalized customization for individuals of different identities.
AI image generation
155.1K
Fresh Picks
Musev
MuseV is a diffusion model-based virtual human video generation framework that supports the generation of unlimited length videos. It utilizes a novel visual conditional parallel denoising approach. It provides a pre-trained virtual human video generation model, supporting functionalities like Image2Video, Text2Image2Video, and Video2Video. MuseV is compatible with the Stable Diffusion ecosystem, including base models, LoRA, ControlNet, and more. It supports multi-reference image techniques such as IPAdapter, ReferenceOnly, ReferenceNet, and IPAdapterFaceID. MuseV's strength lies in its ability to generate high-fidelity, unlimited length videos, specifically targeting the video generation domain.
AI video generation
443.5K
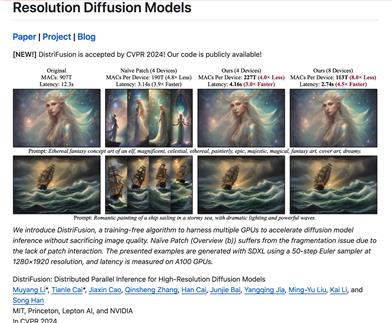
Distrifusion
DistriFusion is an algorithm that requires no training and takes advantage of multiple GPUs to accelerate diffusion model inference without compromising image quality. DistriFusion can reduce delay based on the number of devices used while maintaining visual fidelity.
AI image generation
78.1K

Sora
AI video generation
17.1M
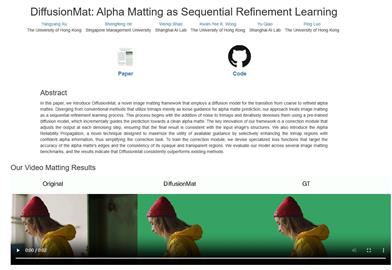
Diffusionmat
DiffusionMat is a novel image matting framework that uses a diffusion model to transform rough to fine alpha matting. Unlike traditional methods, our approach treats image matting as a gradual learning process, starting from adding noise to the trimmed map and iteratively denoising through a pre-trained diffusion model, gradually guiding the prediction towards a clean alpha matting. A key innovation in our framework is a correction module, which adjusts the output in each denoising step to ensure that the final result aligns with the structure of the input image. We also introduce Alpha Reliability Propagation, a novel technique aimed at maximizing the utility of available guidance by selectively enhancing the alpha information in the trimmed map regions with confidence, thus simplifying the correction task. To train the correction module, we have designed a specific loss function to target the accuracy of alpha matting edges and the consistency of opaque and transparent areas. We have evaluated our model on several image matting benchmarks, and the results show that DiffusionMat always outperforms existing methods.
AI Image Editing
74.5K
Graphmaker
GraphMaker is a diffusion model designed for generating large property graphs. It can generate both node attributes and graph structures simultaneously, or generate node attributes first and then the graph structure. Supported datasets include cora, citeseer, amazon_photo, and amazon_computer. You can leverage pre-trained models to generate graphs.
AI Model
54.4K
Featured AI Tools
English Picks

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
50.0K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
45.5K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
43.3K
Chinese Picks

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
43.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
45.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
43.3K
English Picks

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
Chinese Picks

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M