%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# 3D Reconstruction
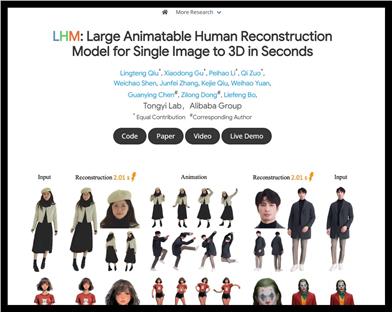
LHM
LHM (Large-scale Animatable Human Reconstruction Model) utilizes a multimodal transformer architecture for high-fidelity 3D head reconstruction, supporting the generation of animatable 3D human characters from a single image. The model can accurately preserve clothing geometry and texture, and is particularly excellent at restoring facial identity and details, making it suitable for application scenarios with high requirements for 3D reconstruction accuracy.
3D Modeling
62.7K
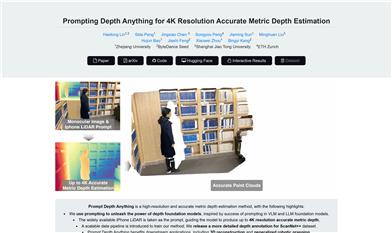
Prompt Depth Anything
Prompt Depth Anything is a method for high-resolution and high-precision depth estimation. This method unlocks the potential of depth foundational models through prompting techniques, using iPhone LiDAR as a cue to guide the model in generating precise depth measurements of up to 4K resolution. Additionally, it introduces a scalable data pipeline for training and has released a more detailed ScanNet++ dataset with depth annotations. The main advantages of this technology include high-resolution and high-precision depth estimation, along with benefits for downstream applications such as 3D reconstruction and generalized robotic grasping.
3D Modeling
51.1K
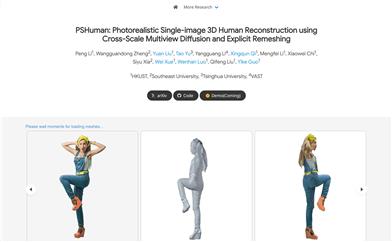
Pshuman
PSHuman is an innovative framework that utilizes multi-view diffusion models and explicit reconstruction techniques to reconstruct realistic 3D human models from a single image. Its significance lies in its ability to handle complex self-occlusion issues and avoid geometric distortions in the generated facial details. PSHuman achieves richly detailed new perspective generation while maintaining identity features by jointly modeling global body shapes and local facial characteristics with cross-scale diffusion models. Additionally, PSHuman enhances cross-view body shape consistency under different human postures using physical priors provided by parameterized models like SMPL-X. Key advantages of PSHuman include rich geometric details, high texture fidelity, and strong generalization capability.
3D Modeling
78.9K
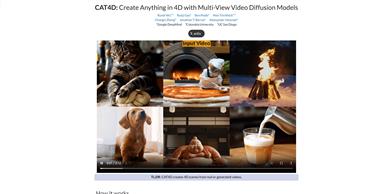
CAT4D
CAT4D is a cutting-edge technology that generates 4D scenes from monocular videos using multi-view video diffusion models. It transforms input monocular videos into multi-perspective video and reconstructs dynamic 3D scenes. The significance of this technology lies in its ability to extract and reconstruct complete spatial and temporal information from single-view video footage, providing robust technical support for virtual reality, augmented reality, and 3D modeling. Background information indicates that CAT4D is a collaborative project developed by researchers from Google DeepMind, Columbia University, and UC San Diego, representing a successful case of turning advanced research outcomes into practical applications.
3D Modeling
63.2K
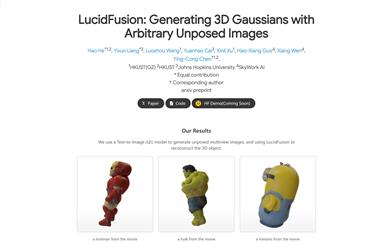
Lucidfusion
LucidFusion is a flexible end-to-end feedforward framework designed for generating high-resolution 3D Gaussians from unposed, sparse, and any number of multi-view images. This technology uses Relative Coordinate Maps (RCM) to align geometric features between different views, providing a high degree of adaptability for 3D generation. LucidFusion integrates seamlessly with traditional single-image-to-3D processes, producing detailed 3D Gaussians at 512x512 resolution suitable for a wide range of applications.
3D modeling
54.4K

Long LRM
Long-LRM is a model designed for 3D Gaussian reconstruction, capable of recreating large scenes from a series of input images. The model can process 32 images at a resolution of 960x540 in just 1.3 seconds, operating on a single A100 80G GPU. It integrates the latest Mamba2 modules with traditional transformer modules to enhance efficiency without compromising quality through effective token merging and Gaussian trimming. Unlike traditional feedforward models that can only reconstruct small portions of a scene, Long-LRM can regenerate the entire scene in one go. On large-scale scene datasets like DL3DV-140 and Tanks and Temples, Long-LRM's performance is comparable to optimization-based methods while achieving two orders of magnitude greater efficiency.
3D modeling
60.4K

Flex3d
Flex3D features a two-stage process that generates high-quality 3D assets from a single image or text prompt. This technology represents the latest advancements in the field of 3D reconstruction, significantly improving the efficiency and quality of 3D content generation. Flex3D is developed with support from Meta, and the team has a strong background in 3D reconstruction and computer vision.
AI 3D tools
66.5K
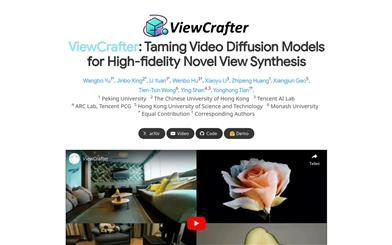
Viewcrafter
ViewCrafter is an innovative approach that leverages the generative capabilities of video diffusion models and the coarse 3D cues provided by point-based representations to synthesize high-fidelity new viewpoints of general scenes from single or sparse images. The method progressively expands the area covered by 3D cues and new viewpoints through iterative view synthesis strategies and camera trajectory planning algorithms, thereby increasing the generation range of new viewpoints. ViewCrafter can facilitate various applications, such as creating immersive experiences and real-time rendering by optimizing 3D-GS representations, as well as promoting imaginative content creation through scene-level text-to-3D generation.
AI image generation
62.7K

Omnire
OmniRe is a comprehensive method for efficiently reconstructing high-fidelity dynamic urban scenes from device logs. This technology achieves a complete reconstruction of different objects in the scene by constructing a dynamic neural scene graph based on Gaussian representations and building multiple local canonical spaces to simulate various dynamic actors, including vehicles, pedestrians, and cyclists. OmniRe enables comprehensive reconstruction of different objects present in a scene, allowing for real-time simulation of reconstructed scenes involving all participants. Extensive evaluations on the Waymo dataset show that OmniRe significantly outperforms previous state-of-the-art methods both quantitatively and qualitatively.
AI image generation
54.1K
Fresh Picks
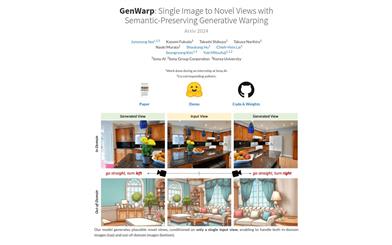
Genwarp
GenWarp is a model designed for generating new viewpoint images from a single image. It employs a semantically-preserving generative deformation framework that allows text-to-image generation models to learn where deformation and generation should occur. This model addresses the limitations of existing methods by enhancing cross-view attention and self-attention, leveraging conditional generative models on the source view image, and incorporating geometric deformation signals to improve performance across different field scenarios.
AI Image Generation
72.6K

Ouroboros3d
Ouroboros3D is a unified 3D generation framework that integrates multi-view image generation and 3D reconstruction into a single recursive diffusion process. The framework jointly trains the two modules via a self-supervised mechanism, enabling them to adapt to each other and achieve robust inference. During multi-view denoising, the multi-view diffusion model utilizes 3D-aware rendered images from the reconstruction module at the previous timestep as additional conditioning. The combination of the recursive diffusion framework with 3D-aware feedback improves the overall geometric consistency of the process. Experiments demonstrate that the Ouroboros3D framework outperforms both separate training of the two stages and existing methods that combine them at inference time.
AI image generation
66.8K
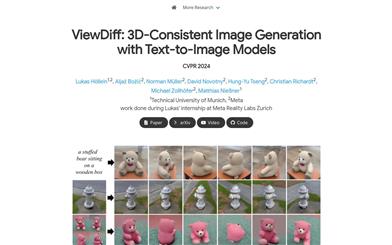
Viewdiff
ViewDiff is a method for generating multi-view consistent images from real-world data by leveraging pre-trained text-to-image models as prior knowledge. It incorporates 3D volume rendering and cross-frame attention layers into the U-Net network, enabling the generation of 3D-consistent images in a single denoising process. Compared to existing methods, ViewDiff generates results with better visual quality and 3D consistency.
AI image generation
86.9K

Diffhuman
DiffHuman is a probabilistic, photorealistic 3D human reconstruction method. It can predict a probability distribution of 3D human reconstructions from a single RGB image and generate multiple detailed and colorful 3D human models through iterative denoising sampling. Compared to existing deterministic methods, DiffHuman can generate more detailed reconstructions in unknown or uncertain areas. We also introduce an accelerated rendering generative network, significantly improving inference speed.
AI image generation
62.9K

GRM
GRM is a large-scale reconstruction model that can recover 3D assets from sparse view images in 0.1 seconds and achieve generation in 8 seconds. It is a feed-forward Transformer-based model that can efficiently fuse multi-view information to convert input pixels into pixel-aligned Gaussian distributions. These Gaussian distributions can be back-projected into a dense 3D Gaussian distribution collection representing the scene. Our Transformer architecture and the use of 3D Gaussian distributions unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate that our method surpasses other alternatives in terms of reconstruction quality and efficiency. We also showcase GRM's potential in generation tasks (such as text-to-3D and image-to-3D) by combining it with existing multi-view diffusion models.
AI image generation
62.7K
Triposr
TripoSR, a 3D object reconstruction model developed by Stability AI and Tripo AI, can generate high-quality 3D models from a single image in less than a second. The model runs with low inference budget and does not require a GPU, making it suitable for a wide range of users and application scenarios. The model weights and source code are released under the MIT license, allowing for commercial, personal, and research use.
AI Model
423.1K
Dust3r
DUSt3R is a novel dense and unconstrained stereo 3D reconstruction method applicable to any image set. It does not require prior knowledge of camera calibration or viewpoint pose information. By treating the pairwise reconstruction problem as a point cloud regression, DUSt3R relaxes the strict constraints of traditional projective camera models. DUSt3R provides a unified approach for both monocular and binocular reconstruction and proposes a simple and effective global alignment strategy for multi-image cases. The network architecture is built based on standard Transformer encoder and decoder, leveraging the power of pre-trained models. DUSt3R directly provides the 3D model and depth information of the scene and can recover pixel-wise matches, relative and absolute camera information from it.
3D Modeling
364.6K

Visfusion
VisFusion is a technology that utilizes video data for online 3D scene reconstruction. It can extract and reconstruct a three-dimensional environment in real-time from videos. This technology combines computer vision and deep learning to provide users with a powerful tool for creating precise 3D models.
AI 3D tools
68.2K
PRISMA
PRISMA is a computational photography pipeline that can perform a variety of inferences from any image or video. Similar to how light is refracted into different wavelengths through a prism, this pipeline expands images into data usable for 3D reconstruction or real-time post-processing operations. It integrates various algorithms and open-source pretrained models, such as monocular depth (MiDAS v3.1, ZoeDepth, Marigold, PatchFusion), optical flow (RAFT), segmentation masks (mmdet), and camera pose estimation (colmap), among others. The results are stored in a folder with the same name as the input file, with each band saved as a separate .png or .mp4 file. For videos, in the final step, it attempts to perform sparse reconstruction, which can be used for NeRFs (such as NVidia's Instant-ngp) or Gaussian diffusion training. The inferred depth information is exported by default as heatmap GLSL/HLSL samples that can be decoded in real-time using LYGIA, and the optical flow is encoded as HUE (angle) and saturation, which can also be decoded in real-time using LYGIA's optical flow GLSL/HLSL sampler.
AI Image Generation
61.3K
SIFU
SIFU is a method for reconstructing high-quality 3D virtual human models from lateral images. Its core innovation lies in proposing a new implicit function based on lateral images, which enhances feature extraction and improves geometric accuracy. Additionally, SIFU introduces a 3D consistent texture optimization process that significantly enhances texture quality and enables texture editing through a text-to-image diffusion model. SIFU excels in handling complex poses and loose clothing, making it an ideal solution for practical applications.
AI image generation
72.0K
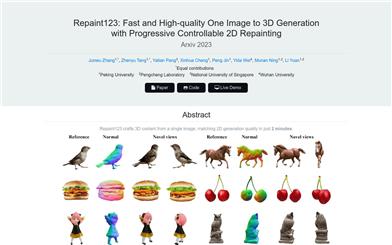
Repaint123
Repaint123 can generate high-quality, multi-view consistent 3D content in just 2 minutes from a single image. It combines the robust image generation capability of the 2D scattering model with the texture alignment ability of the progressive redraw strategy, creating high-quality, visually consistent multi-view images. It enhances the image quality during the redraw process by adjusting the redraw intensity based on visibility perception, making the generation of high-quality, multi-view consistent images achievable with a simple mean squared error loss function. The resulting high-quality, multi-view consistent images enable the rapid generation of 3D content.
AI image generation
65.4K
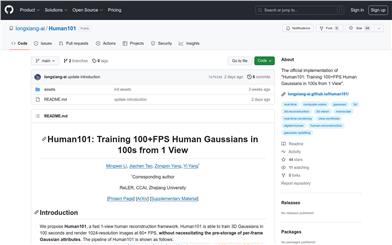
Human101
Human101 is a framework for quickly reconstructing human figures from a single view. It can train a 3D Gaussian model within 100 seconds and render images at a resolution of 1024 and above 60FPS without pre-saving the Gaussian properties of each frame. The Human101 pipeline is as follows: first, extract 2D human pose from the single-view video. Then, use the pose to drive a 3D simulator to generate corresponding 3D skeletal animation. Finally, construct a time-varying 3D Gaussian model based on the animation for real-time rendering.
AI image generation
109.0K

Gaussian SLAM
Gaussian SLAM is capable of reconstructing renderable 3D scenes from RGBD data streams. It is the first neural RGBD SLAM method capable of reconstructing real-world scenes with photorealistic fidelity. By leveraging 3D Gaussian as the primary unit for scene representation, we overcome the limitations of previous methods. We observe that traditional 3D Gaussians are difficult to utilize in monocular settings: they fail to encode accurate geometric information and are challenging to optimize sequentially with single-view supervision. By extending traditional 3D Gaussians to encode geometric information and designing a novel scene representation as well as a method for its growth and optimization, we propose an SLAM system that can reconstruct and render real-world datasets while maintaining speed and efficiency. Gaussian SLAM is able to reconstruct and render real-world scenes with photorealistic fidelity. We evaluate our method on common synthetic and real-world datasets, comparing it against other state-of-the-art SLAM methods. Finally, we demonstrate that the resulting 3D scene representation can be efficiently rendered in real-time using Gaussian splatting.
3D Modeling
51.9K

Reconfusion
ReconFusion is a 3D reconstruction method that leverages diffusion priors to reconstruct real-world scenes from a limited number of photographs. It combines Neural Radiance Fields (NeRFs) with diffusion priors, enabling the synthesis of realistic geometry and textures at new camera poses beyond the input image set. This method is trained on diffusion priors with both limited-view and multi-view datasets, allowing it to synthesize realistic geometry and textures in unconstrained regions while preserving the appearance of the observed region. ReconFusion has been extensively evaluated on various real-world datasets, including forward and 360-degree scenes, demonstrating significant performance improvements.
AI image generation
62.4K
Nvas3d
NVAS3d is a project for estimating sound at any location within a scene containing multiple unknown sound sources. It achieves novel-view acoustic synthesis by using audio recordings from multiple microphones and the 3D geometry and materials of the scene.
AI Audio Enhancer
52.7K
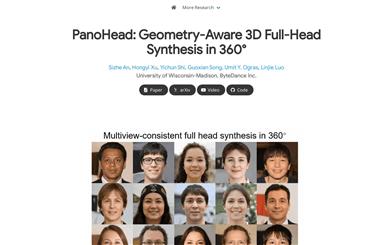
Panohead
PanoHead is a 360° geometric sensory 3D full head synthesis method that can be trained solely using unstructured outdoor images to achieve consistent 360° full-body head image synthesis with various appearances and detailed geometric shapes.
AI image generation
74.0K

Chupa
Chupa is a 3D human generation pipeline that combines the generation capabilities of diffusion models with neural rendering techniques to create diverse and realistic 3D human figures. The pipeline can easily generalize to unseen human poses and produce lifelike results. Chupa generates a variety of high-quality 3D human meshes from the SMPL-X grid in the latent space.
AI image generation
53.3K

Neuralangelo By NVIDIA
Neuralangelo is an AI model developed by NVIDIA Research that uses neural networks for 3D reconstruction. It can convert 2D video clips into detailed 3D structures, generating realistic virtual buildings, sculptures, and other objects. It accurately captures the textures of complex materials, including roof tiles, glass window panes, and polished marble. Creative professionals can import these 3D objects into design applications for further editing, using them in art, video game development, robotics, and industrial digital twins. Neuralangelo's 3D reconstruction capabilities will greatly benefit creators by enabling them to re-create the real world in the digital realm. Ultimately, this tool will allow developers to integrate detailed objects (ranging from small sculptures to large buildings) into virtual environments for applications such as video games or industrial digital twins.
AI 3D tools
71.5K
Featured AI Tools
English Picks

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
50.0K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
45.5K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
43.3K
Chinese Picks

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
43.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
45.5K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
43.1K
English Picks

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
Chinese Picks

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M