%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Self-Supervised Learning
SHMT
SHMT is a self-supervised hierarchical makeup transfer technology achieved through latent diffusion models. This technology allows for the natural transfer of one facial makeup to another without the need for explicit labeling. Its main advantages include the ability to handle complex facial features and expression changes, providing high-quality transfer results. This technology has been accepted at NeurIPS 2024, showcasing its innovation and practicality in the field of image processing.
AI design tools
44.4K
1.58 Bit FLUX
1.58-bit FLUX is an advanced text-to-image generation model that employs 1.58-bit weights (values of {-1, 0, +1}) to quantify the FLUX.1-dev model while maintaining comparable performance for generating 1024x1024 images. This method does not require access to image data and relies entirely on the self-supervision of the FLUX.1-dev model. Additionally, a custom kernel has been developed to optimize 1.58-bit operations, achieving a 7.7x reduction in model storage, a 5.1x decrease in inference memory, and improved inference latency. Extensive evaluations in GenEval and T2I Compbench benchmarks show that 1.58-bit FLUX significantly enhances computational efficiency while maintaining generation quality.
Image Generation
75.6K

Video Foley
Video-Foley is an innovative system for generating sound from video. It employs root mean square (RMS) as a temporal event condition, combined with semantic tonal prompts (audio or text), to achieve high control and synchronization in video sound synthesis. The system utilizes an unsupervised learning framework that requires no manual labeling, consisting of two stages: Video2RMS and RMS2Sound, incorporating novel concepts such as RMS discretization and RMS-ControlNet, in conjunction with a pre-trained text-to-audio model. Video-Foley achieves state-of-the-art performance in aligning and controlling sound timing, intensity, timbre, and detail.
AI video generation
54.6K
Fresh Picks
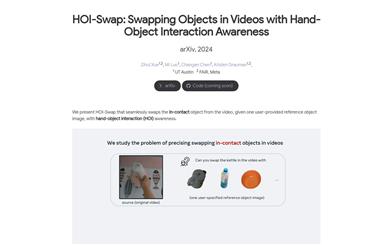
HOI Swap
HOI-Swap is a diffusion model-based video editing framework specializing in tackling the complexities of hand-object interactions in video editing. This model, trained through self-supervision, enables seamless object swapping within a single frame. It also learns to adjust hand interaction patterns based on object attribute changes, such as grip style. The second stage extends single-frame editing to an entire video sequence, achieving high-quality video editing through motion alignment and video generation.
Video Editing
51.1K
Fresh Picks
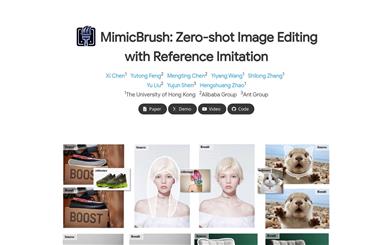
Mimicbrush
MimicBrush is an innovative image editing model that allows users to achieve zero-shot image editing by specifying the editing area in the source image and providing a reference image. The model can automatically capture the semantic correspondence between the two images and complete the editing in one step. MimicBrush is developed based on diffusion priors, capturing semantic relationships between different images through self-supervised learning, and experimental results demonstrate its effectiveness and superiority in various test cases.
AI image editing
473.3K

Denseav
DenseAV is a novel dual-encoder localization architecture that learns high-resolution, semantically meaningful audio-visual alignment features by observing videos. It can discover the "meaning" of words and the "location" of sounds without requiring explicit localization supervision, and automatically discovers and distinguishes between these two types of associations. DenseAV's localization capability stems from a new multi-head feature aggregation operator, which directly compares dense image and audio representations through contrastive learning. Additionally, DenseAV significantly outperforms previous art on semantic segmentation tasks and surpasses ImageBind in cross-modal retrieval using less than half the parameters.
Video Editing
51.9K

Anitalker
AniTalker is an innovative framework that can generate realistic dialogue facial animations from a single portrait. It enhances expressive motion capture through two self-supervised learning strategies, and develops an identity encoder through metric learning, effectively reducing the need for labeled data. AniTalker not only creates detailed and realistic facial expressions but also emphasizes its potential in real-world applications for producing dynamic avatars.
AI head portrait generation
115.1K
Miqu 1 70b
Miqu 1-70b is an open-source large language model that utilizes novel self-supervised learning methods, capable of handling a variety of natural language tasks. With 170 billion parameters, it supports multiple prompt formats and allows for fine-tuning to generate high-quality text. Its strong comprehension and generation capabilities make it suitable for applications in chatbots, text summarization, question answering systems, and other domains.
AI Model
116.7K
A Vision Check Up
This paper systematically evaluates the ability of large language models (LLMs) to generate and recognize increasingly complex visual concepts, and demonstrates how to train initial visual representation learning systems using text models. Although language models cannot directly process pixel-level visual information, this research utilizes code representations of images. While LLM-generated images are not like natural images, the results on image generation and correction suggest that accurately modeling strings can teach language models much about the visual world. Furthermore, experiments on self-supervised visual representation learning using text-model generated images highlight the potential of training visual models capable of semantic evaluation on natural images using only LLMs.
AI Science Research
48.0K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
45.5K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.3K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
44.2K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
43.6K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.6K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M