%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Deep Learning

Omniavatar
OmniAvatar is an advanced audio-driven video generation model that can generate high-quality virtual character animations. Its importance lies in combining audio and visual content to achieve efficient body animation, applicable to various scenarios. This technology uses deep learning algorithms to achieve high-fidelity animation generation, supports multiple input formats, and is positioned for the film, gaming, and social media sectors. The model is open source, promoting technology sharing and application.
Video Animation
37.0K
English Picks

Veo 3
Veo 3 is the latest video generation model designed to provide 4K output through higher realism and audio effects, accurately following user prompts. This technology represents a significant advancement in the field of video generation, with stronger creative control capabilities. The release of Veo 3 is an important upgrade from Veo 2, aimed at helping creators realize their creative visions. The product is suitable for creative industries that require high-quality video generation, from advertising to game development. No specific price information is disclosed.
Deep Learning
38.1K

Blip 3o
Blip 3o is an application built on the Hugging Face platform that uses advanced generative models to create images from text or analyze and answer questions about existing images. This product provides users with powerful image generation and understanding capabilities, making it ideal for designers, artists, and developers. The main advantages of this technology are its efficient image generation speed and high-quality outputs, as well as its support for multiple input formats, which enhances user experience. The product is free and open to all users.
Image Generation
40.3K

Dreamo
DreamO is an advanced image customization model designed to enhance image generation fidelity and flexibility. The framework combines VAE feature encoding, making it applicable to various inputs, particularly excelling in preserving character identity. It supports consumer-grade GPUs, has 8-bit quantization and CPU offloading capabilities, and adapts to different hardware environments. Continuous updates to the model have made progress in addressing issues like oversaturation and plasticity in faces, aiming to provide users with a higher quality image generation experience.
Image Generation
39.5K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Deerflow
DeerFlow is a deep research framework aimed at combining language models with specialized tools like web search, crawling, and Python execution to promote in-depth research work. This project originates from the open-source community, emphasizing contribution feedback, and has various flexible features suitable for different research needs.
Open Source
37.3K

Keysync
KeySync is a leak-free lip-sync framework for high-resolution videos. It addresses the issue of temporal consistency in traditional lip-sync technologies while using a clever masking strategy to handle expression leakage and facial occlusion. KeySync excels in its advanced results in lip reconstruction and cross-synchronization, applicable to practical scenarios such as automatic dubbing.
Video Editing
40.8K

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition
38.6K

Camerabench
CameraBench is a model for analyzing camera motion in videos, aimed at understanding the motion patterns of cameras through video interpretation. Its main advantage lies in using generative visual language models for principle classification of camera motions and video-text retrieval. Compared with traditional Structure from Motion (SfM) and Simultaneous Localization and Mapping (SLAM) methods, this model shows significant advantages in capturing scene semantics. The model is open-source and suitable for use by researchers and developers, with more improved versions to be released later.
Research Tools
39.5K
English Picks

F Lite
F Lite is a large diffusion model developed by Freepik and Fal with 10 billion parameters, specifically trained on copyright-safe and Suitable For Work (SFW) content. The model is based on Freepik's internal dataset, which contains about 80 million legally compliant images, marking the first time that publicly available models at this scale have focused on legal and safe content. Its technical report provides detailed information about the model and it is distributed under the CreativeML Open RAIL-M license. The design of the model aims to promote the openness and accessibility of AI.
Image Generation
41.4K

Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
39.2K

Describe Anything
The Describe Anything model (DAM) can process specific regions of images or videos and generate detailed descriptions. Its main advantage lies in its ability to generate high-quality localized descriptions through simple markings (points, boxes, scribbles, or masks), greatly enhancing image understanding capabilities in the field of computer vision. The model was jointly developed by NVIDIA and several universities and is suitable for research, development, and practical applications.
Image Generation
39.7K
English Picks

Flex.2 Preview
Flex.2 is currently the most flexible text-to-image diffusion model, featuring built-in inpainting and general control capabilities. It is an open-source project, community-supported, and aims to democratize artificial intelligence. Flex.2 has 800 million parameters, supports 512 token length input, and is compliant with the OSI's Apache 2.0 license. This model can provide powerful support in many creative projects. Users can continuously improve the model through feedback, driving technological progress.
Image Generation
40.6K
Nes2net
Nes2Net is a lightweight nested architecture designed for foundation model-driven speech anti-fraud tasks, featuring a low error rate and suitability for audio deepfake detection. This model performs excellently on multiple datasets, and the pre-trained model and code have been released on GitHub for easy use by researchers and developers. Suitable for audio processing and security fields, it primarily aims to improve the efficiency and accuracy of speech recognition and anti-fraud.
Safety
37.5K

D1
This model improves the reasoning capabilities of diffusion large language models through reinforcement learning and masked self-supervised fine-tuning with high-quality reasoning trajectories. The importance of this technology lies in its ability to optimize the model's reasoning process, reduce computational costs, while ensuring the stability of learning dynamics. Suitable for users who want to improve efficiency in writing and reasoning tasks.
Writing Assistant
42.2K
Chinese Picks

Wan2.1 FLF2V 14B
Wan2.1-FLF2V-14B is an open-source, large-scale video generation model designed to advance the field of video generation. This model excels in multiple benchmark tests, supports consumer-grade GPUs, and efficiently generates 480P and 720P videos. It performs exceptionally well in various tasks, including text-to-video and image-to-video, possessing strong visual-text generation capabilities suitable for diverse real-world applications.
Video Production
39.7K

Framepack
FramePack is an innovative video generation model designed to improve the quality and efficiency of video generation by compressing the context of input frames. Its main advantage lies in addressing the drift problem in video generation, maintaining video quality through a bidirectional sampling method, and being suitable for users who need to generate long videos. This technology is based on in-depth research and experiments on existing models to improve the stability and coherence of video generation.
Video Production
38.4K

Liquid
Liquid is an autoregressive generative model that facilitates seamless integration of visual understanding and text generation by decomposing images into discrete codes and sharing feature space with text tokens. The main advantage of this model is the elimination of the need for externally pre-trained visual embeddings, reducing resource dependence, while simultaneously discovering a synergistic effect between understanding and generation tasks through the law of scaling.
Image Generation
40.8K
Chinese Picks

GLM 4 32B
GLM-4-32B is a high-performance generative language model designed to handle various natural language tasks. Trained using deep learning techniques, it can generate coherent text and answer complex questions. This model is suitable for academic research, commercial applications, and developers. It is reasonably priced, precisely positioned, and a leading product in the field of natural language processing.
AI Model
40.3K

Pusa
Pusa introduces an innovative approach to video diffusion modeling through frame-level noise control, enabling high-quality video generation suitable for various tasks (text-to-video, image-to-video, etc.). With its superior motion fidelity and efficient training process, the model offers an open-source solution for convenient video generation.
Video Production
38.9K

UNO
UNO is a multi-image conditional generation model based on diffusion transformers. By introducing progressive cross-modal alignment and universal rotational positional embedding, it achieves highly consistent image generation. Its main advantages lie in enhanced controllability over the generation of single or multiple subjects, making it suitable for various creative image generation tasks.
Image Generation
41.4K
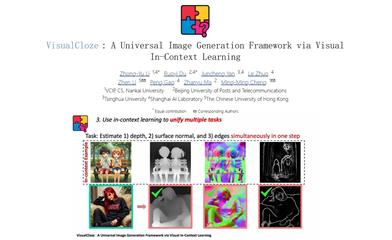
Visualcloze
VisualCloze is a general-purpose image generation framework that learns through visual context, aiming to address the inefficiency of traditional task-specific models under diverse needs. This framework not only supports multiple internal tasks but can also generalize to unseen tasks, using visual examples to help the model understand the task. This approach leverages the strong generative priors of advanced image inpainting models, providing strong support for image generation.
Image Generation
40.0K
Skyreels A2
SkyReels-A2 is a framework based on a video diffusion transformer that allows users to synthesize and generate video content. The model, leveraging deep learning technology, provides flexible creative capabilities suitable for various video generation applications, especially in animation and special effects production. The product's advantages lie in its open-source nature and efficient model performance, making it suitable for researchers and developers. It is currently free of charge.
Video Production
39.7K

Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
39.7K

Easycontrol
EasyControl is a framework that provides efficient and flexible control for Diffusion Transformer (DiT), aiming to solve the efficiency bottlenecks and lack of model adaptability in the current DiT ecosystem. Its main advantages include: supporting multiple conditional combinations, improving generation flexibility and inference efficiency. This product is developed based on the latest research results and is suitable for use in image generation, style transfer, and other fields.
AI Model
38.6K

Dreamactor M1
DreamActor-M1 is a human animation framework based on Diffusion Transformer (DiT), designed to achieve fine-grained overall controllability, multi-scale adaptability, and long-term temporal consistency. The model, through blending guidance, can generate high-expressiveness and realistic human videos suitable for various scenarios from portrait to full-body animation. Its main advantages lie in its high fidelity and identity preservation, bringing new possibilities to human behavior animation.
Video Production
37.8K
Chinese Picks

QVQ Max
QVQ-Max is a visual reasoning model launched by the Qwen team, capable of understanding and analyzing image and video content to provide solutions. It is not limited to text input but can also handle complex visual information. Suitable for users who need multi-modal information processing, such as in education, work, and life scenarios. This product is developed based on deep learning and computer vision technology and is suitable for students, professionals, and creative individuals. This is the initial release, and subsequent optimizations will be continuous.
AI Model
52.2K
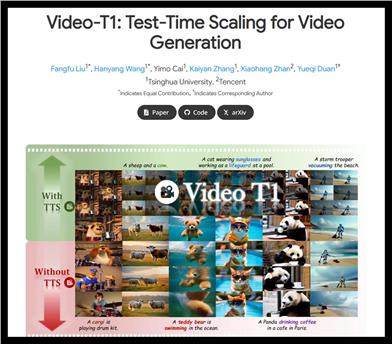
Video T1
Video-T1 is a video generation model that significantly improves the quality and consistency of generated videos through test-time scaling (TTS) technology. This technology allows more computational resources to be used during inference, thereby optimizing the generation results. Compared to traditional video generation methods, TTS can provide higher generation quality and richer content expression, suitable for the digital creation field. This product is mainly aimed at researchers and developers, and the price information is not clear.
Video Production
54.9K
RF DETR
RF-DETR is a transformer-based real-time object detection model designed for high accuracy and real-time performance on edge devices. It surpasses 60 AP on the Microsoft COCO benchmark, boasting competitive performance and fast inference speed, suitable for various real-world applications. RF-DETR aims to solve real-world object detection problems and is applicable to industries requiring efficient and accurate detection, such as security, autonomous driving, and intelligent monitoring.
Target Detection
63.5K
Chinese Picks
Hunyuan T1
HunYuan T1 is a large-scale reasoning model launched by Tencent, based on reinforcement learning technology, significantly improving reasoning capabilities through extensive post-training. It excels in long text processing and context capture, while optimizing the consumption of computing resources, thus possessing efficient reasoning capabilities. It is suitable for various reasoning tasks, and particularly excels in mathematics and logical reasoning. This product is based on deep learning and continuously optimized with actual feedback, suitable for applications in various fields such as scientific research and education.
AI Model
65.4K
- 1
- 2
- 3
- 4
- 5
- 6
- 10
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K
Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M