%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
EN

AI Powered Live Captioning System
Overview :
AI Real-Time Captioning Service is an AI-powered online captioning service that can provide real-time captions and interactive transcriptions for meetings or conferencing services. It can be easily integrated into your service without programming. Supporting multiple languages and dialects, it provides real-time caption data to enhance the accessibility and user experience of meetings.
Target Users :
Suitable for various meetings and conferencing services, such as online meetings, video conferencing, and remote education.
Features
Real-time captions and interactive transcription
Fast integration into existing services
Support for multiple languages and dialects
Provide real-time caption data
Enhance meeting accessibility and user experience
Traffic Sources
| Direct Visits | 0.00% | External Links | 0.00% | 0.00% | |
| Organic Search | 0.00% | Social Media | 0.00% | Display Ads | 0.00% |
Latest Traffic Situation
| Monthly Visits | 0 |
| Average Visit Duration | 0.00 |
| Pages Per Visit | 0.00 |
| Bounce Rate | 0 |
Total Traffic Trend Chart
Similar Open Source Products

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition

Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition

Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition

Step Audio
Step-Audio is the first production-level open-source intelligent voice interaction framework, integrating voice understanding and generation capabilities. It supports multilingual dialogue, emotional intonation, dialects, speech rate, and prosodic style control. Its core technologies include a 130B parameter multimodal model, a generative data engine, fine-grained voice control, and enhanced intelligence. This framework promotes the development of intelligent voice interaction technology through open-source models and tools, and is suitable for a variety of voice application scenarios.
Speech Recognition

Fireredasr AED L
FireRedASR-AED-L is an open-source, industrial-grade automatic speech recognition model designed to meet the needs for high efficiency and performance in speech recognition. This model utilizes an attention-based encoder-decoder architecture and supports multiple languages including Mandarin, Chinese dialects, and English. It achieved new record levels in public Mandarin speech recognition benchmarks and has shown exceptional performance in singing lyric recognition. Key advantages of the model include high performance, low latency, and broad applicability across various speech interaction scenarios. Its open-source feature allows developers the freedom to use and modify the code, further advancing the development of speech recognition technology.
Speech Recognition
Fireredasr
FireRedASR is an open-source industrial-grade Mandarin automatic speech recognition model, utilizing an Encoder-Decoder and LLM integrated architecture. It includes two variants: FireRedASR-LLM and FireRedASR-AED, designed for high-performance and efficient needs respectively. The model excels in Mandarin benchmarking tests and also performs well in recognizing dialects and English speech. It is suitable for industrial applications requiring efficient speech-to-text conversion, such as smart assistants and video subtitle generation. The open-source model is easy for developers to integrate and optimize.
Speech Recognition
Pengchengstarling
PengChengStarling is an open-source toolkit focused on multilingual automatic speech recognition (ASR), developed based on the icefall project. It supports the entire ASR process, including data processing, model training, inference, fine-tuning, and deployment. By optimizing parameter configurations and integrating language identifiers into the RNN-Transducer architecture, it significantly enhances the performance of multilingual ASR systems. Its main advantages include efficient multilingual support, a flexible configuration design, and robust inference performance. The models in PengChengStarling perform exceptionally well across various languages, require relatively small model sizes, and offer extremely fast inference speeds, making it suitable for scenarios that demand efficient speech recognition.
Speech Recognition
Realtimestt
RealtimeSTT is an open-source speech recognition model capable of converting spoken language into text in real time. It employs advanced voice activity detection technology to automatically detect the start and end of speech without manual intervention. Additionally, it supports wake word activation, allowing users to initiate speech recognition by saying specific wake words. The model is characterized by low latency and high efficiency, making it suitable for real-time transcription applications such as voice assistants and meeting notes. It is developed in Python, easy to integrate and use, and is open-source on GitHub, with an active community that continuously provides updates and improvements.
Speech Recognition

Minmo
MinMo, developed by Alibaba Group's Tongyi Laboratory, is a multimodal large language model with approximately 8 billion parameters, focused on achieving seamless voice interactions. It is trained on 1.4 million hours of diverse voice data through various stages, including speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and full-duplex interaction alignment. MinMo achieves state-of-the-art performance across various benchmarks in speech understanding and generation, while maintaining the capabilities of text-based large language models and supporting full-duplex dialogues, enabling simultaneous bidirectional communication between users and the system. Additionally, MinMo introduces a novel and straightforward voice decoder that surpasses previous models in speech generation. Its command-following ability has been enhanced to support voice generation control based on user instructions, including details such as emotion, dialect, and speech rate, as well as mimicking specific voices. MinMo's speech-to-text latency is approximately 100 milliseconds, with theoretical full-duplex latency around 600 milliseconds, and actual latency around 800 milliseconds. The development of MinMo aims to overcome the major limitations of previous multimodal models, providing users with a more natural, smooth, and human-like voice interaction experience.
Speech Recognition
Alternatives
Ideately
Ideately is a collaborative platform offering seamless collaboration, intuitive guidance, and artificial intelligence features to drive innovation. Its key advantages include multiple brainstorming and strategy techniques, convenient automation, real-time voting decision-making, and AI-assisted analysis. The product is positioned to improve team creativity and decision-making efficiency.
Meeting Assistant
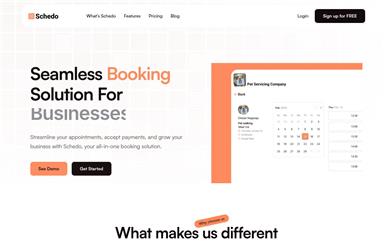
Schedo
Schedo is an AI-powered meeting scheduler that helps users simplify the appointment process, accept payments, and drive business growth. It offers personalized appointment pages, automated reminder features, and customer insights to help users manage appointments more intelligently and quickly.
Meeting Assistant
Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition

Live Portals | Custom Video Conferencing
Live & Interactive Video Conferencing is a powerful video conferencing platform that provides HD video and audio along with real-time features like chat, file sharing, and screen sharing. It supports custom branding, secure and controllable settings, real-time changes, and is suitable for various scenarios including sales, collaboration, and business presentations.
Meeting Assistant
Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
Chinese Picks
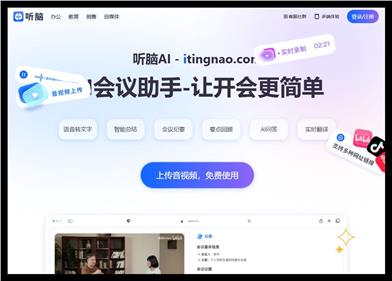
Listenbrain AI
ListenBrain AI is a professional intelligent AI meeting assistant that provides one-stop intelligent meeting services aimed at improving meeting efficiency. It supports real-time meetings, meeting recording, and multilingual translation, and can automatically generate meeting minutes and summaries. This product is suitable for various types of meetings, including offline and online video conferences, and is an important tool for improving work efficiency.
Meeting Assistant

Amazon Nova Sonic
Amazon Nova Sonic is a cutting-edge foundational model that integrates speech understanding and generation, enhancing the natural fluency of human-computer dialogue. This model overcomes the complexities of traditional voice applications, achieving a deeper level of communication understanding through a unified architecture. It is suitable for AI applications across multiple industries and holds significant commercial value. As AI technology continues to develop, Nova Sonic will provide customers with better voice interaction experiences and improved service efficiency.
Speech Recognition
Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
Chinese Picks
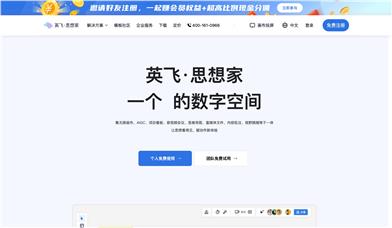
Infie Thinker
Infie Thinker is an AIGC-powered visualized online collaboration space designed to provide enterprises and teams with a highly efficient digital platform for collaboration through features such as infinite canvas, audio and video conferencing, and mind mapping. It supports real-time and asynchronous collaboration and is suitable for various scenarios such as project management, brainstorming, and training. The product is positioned to improve team collaboration efficiency, promote knowledge sharing, and foster innovation. Currently, it offers free personal use and team trials; specific pricing can be found on the official website.
Meeting Assistant
Featured AI Tools
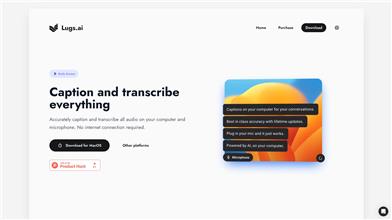
Lugs.ai
Speech Recognition
599.2K
Chinese Picks
REECHO 睿声
REECHO.AI 睿声 is a hyper-realistic AI voice cloning platform. Users can upload voice samples, and the system utilizes deep learning technology to clone voices, generating high-quality AI voices. It allows for versatile voice style transformations for different characters. This platform provides services for voice creation and voice dubbing, enabling more people to participate in the creation of voice content through AI technology and lowering the barrier to entry. The platform is geared towards mass adoption and offers free basic functionality.
Speech Recognition
511.2K