%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Videograin
Overview :
VideoGrain is a diffusion model-based video editing technology that achieves multi-granularity video editing by adjusting the spatiotemporal attention mechanism. This technology addresses the issues of semantic alignment and feature coupling in traditional methods, enabling fine-grained control over video content. Its key advantages include zero-shot editing capabilities, efficient text-to-region control, and feature separation capabilities. This technology is suitable for scenarios requiring complex video editing, such as post-production in film and television and advertising production, significantly improving editing efficiency and quality.
Target Users :
VideoGrain is designed for professionals requiring precise video editing, such as post-production specialists in film and television, advertising creatives, and video content creators. It helps them quickly fulfill complex video editing needs, saving time and costs while enhancing accuracy and artistic effect.
Use Cases
Replacing human characters in a video with superheroes like Spiderman or Iron Man.
Editing animal instances in a video, such as replacing a panda with a toy poodle.
Modifying object parts in a video, such as changing the color of a person's clothing from gray to blue.
Features
Supports category-level, instance-level, and part-level video editing.
Achieves precise editing through enhanced text-to-region control.
Achieves feature separation by adjusting self-attention and cross-attention.
Zero-shot editing capability, requiring no additional training data.
Offers flexible editing for various video content and scenarios.
Supports integration with technologies like SAM-Track for more precise editing.
Provides various experimental results and comparisons to validate its superiority.
Open-source code and data facilitate research and application expansion.
How to Use
1. Access the project page and download the open-source code and relevant data.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Prepare the video to be edited and the corresponding text prompts.
3. Load the video and text prompts using the VideoGrain model.
4. Select the desired editing level (category-level, instance-level, or part-level).
5. Adjust the spatiotemporal attention mechanism for precise editing.
6. Run the model and generate the edited video.
7. Review the editing results and make necessary adjustments.
8. Export the edited video and apply it to your project.


Featured AI Tools
English Picks
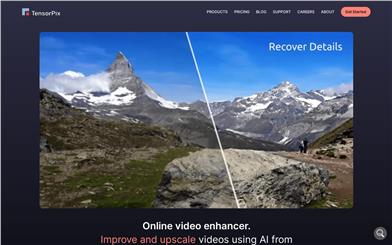
Tensorpix
TensorPix is an online video enhancement platform that employs artificial intelligence technology to improve video quality. It offers a rapid and efficient video upscale service without the need for downloading or installing any software. Users can process videos in bulk, restore colors, clarify details, and correct distortions. Core features include: online resolution enhancement, repairing blur and noise, increasing frame rate, and color enhancement, among others. It is suitable for fixing old recordings and low-quality videos as well as for the post-production refinement of new recorded videos, significantly enhancing video texture with convenience and speed.
Video Editing
6.5M
LTX Studio
LTX Studio is an innovative video production platform integrated with AI technology, which enables users to fully control all aspects of video production from concept to final cut. Through AI technology, the platform transforms creative ideas into coherent video narratives, offering features such as character consistency, automatic editing, and deep frame control, aimed at simplifying the video production process and enhancing creative efficiency.
Video Editing
2.2M