%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Flexheadfa
Overview :
FlexHeadFA is an improved model based on FlashAttention, focusing on providing a fast and memory-efficient accurate attention mechanism. It supports flexible head dimension configuration, significantly enhancing the performance and efficiency of large language models. Key advantages include efficient GPU resource utilization, support for various head dimension configurations, and compatibility with FlashAttention-2 and FlashAttention-3. It is suitable for deep learning scenarios requiring efficient computation and memory optimization, especially excelling in handling long sequences.
Target Users :
This model is ideal for deep learning researchers and developers who need to efficiently process long sequences, particularly those seeking optimized memory and computational efficiency on GPUs. It's applicable to building and optimizing large language models, and natural language processing tasks requiring fast and accurate attention mechanisms.
Use Cases
On an A100 GPU, with a (qk dim, v_dim) = (32, 64) configuration, FlexHeadFA significantly improved model inference speed.
Developers can optimize the model for specific tasks by customizing head dimension configurations.
FlexHeadFA's memory efficiency advantage is particularly noticeable in long sequence data processing tasks, effectively reducing computational costs.
Features
Supports all configurations of FlashAttention-2 and FlashAttention-3.
Offers flexible head dimension configurations, such as various combinations of `QKHeadDim` and `VHeadDim`.
Supports unequal numbers of query, key, and value head configurations.
Supports non-preset head dimensions by automatically generating implementation code.
Provides efficient forward and backward propagation computation, optimizing memory usage.
How to Use
1. Install FlexHeadFA: Use `pip install flex-head-fa --no-build-isolation` or compile from source code.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Replace FlashAttention: Substitute `flash_attn` with `flex_head_fa` in your code.
3. Configure Head Dimensions: Set the `QKHeadDim` and `VHeadDim` parameters according to your needs.
4. Use the Model: Call `flex_head_fa.flash_attn_func` for forward computation.
5. Custom Implementation: For unsupported head dimensions, use the autotuner to automatically generate implementation code.









Featured AI Tools
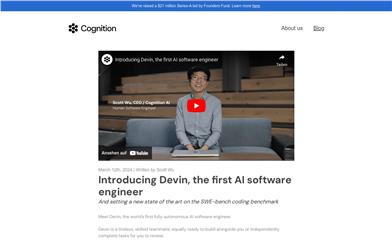
Devin
Devin is the world's first fully autonomous AI software engineer. With long-term reasoning and planning capabilities, Devin can execute complex engineering tasks and collaborate with users in real time. It empowers engineers to focus on more engaging problems and helps engineering teams achieve greater objectives.
Development and Tools
1.7M
Chinese Picks

Foxkit GPT AI Creation System
FoxKit GPT AI Creation System is a completely open-source system that supports independent secondary development. The system framework is developed using ThinkPHP6 + Vue-admin and provides application ends such as WeChat mini-programs, mobile H5, PC website, and official accounts. Sora video generation interface has been reserved. The system provides detailed installation and deployment documents, parameter configuration documents, and one free setup service.
Development and Tools
752.4K