%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Recurrent Pretraining
Overview :
This product consists of a pretraining codebase for large-scale deep recurrent language models, developed in Python. It is optimized for AMD GPU architecture, enabling efficient operation on 4096 AMD GPUs. The core strength of this technology lies in its deep recurrent architecture, which significantly enhances the model's inference capabilities and efficiency. It is primarily aimed at researching and developing high-performance natural language processing models, especially in scenarios requiring large-scale computational resources. The codebase is open-source and licensed under the Apache-2.0 License, making it suitable for academic research and industrial applications.
Target Users :
This product is suitable for scholars, developers engaged in natural language processing research, and enterprises requiring high-performance computing resources. It efficiently trains deep recurrent language models on large-scale GPU clusters, making it ideal for scenarios demanding strong inference capabilities and computational efficiency, such as language generation and text understanding.
Use Cases
Researchers use this model for large-scale language model pretraining to improve performance.
Companies leverage this technology to optimize training workflows for language models on AMD GPU clusters, reducing computational costs.
Developers create customized language models based on this codebase for specific text generation tasks.
Features
Supports large-scale distributed training, capable of running on 4096 AMD GPUs.
Deep recurrent architecture enhances model inference capabilities.
Optimized communication mechanisms to address communication bottlenecks in large-scale training.
Complete pretraining workflow, including data preparation and model evaluation.
Developed with PyTorch for easy extension and modification.
Provides comprehensive training configuration and environment setup instructions.
How to Use
1. Clone the repository to your local environment.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Configure the environment according to the documentation, including installing dependencies and setting environment variables.
3. Prepare training data and use scripts from `scripts/` for data preprocessing.
4. Modify configuration files in `launch_configs/` to suit your hardware environment.
5. Run `train.py` to start the training process.
6. Evaluate the trained model using scripts found in `evaluate_raven/`.
7. Adjust the model architecture or training parameters as needed to optimize performance.


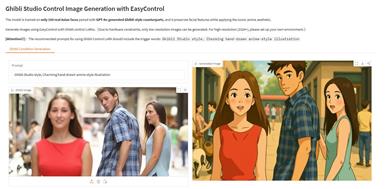







Featured AI Tools
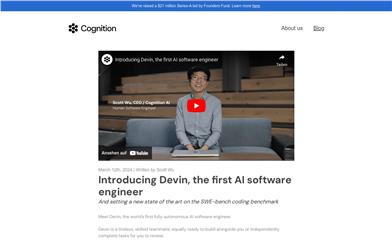
Devin
Devin is the world's first fully autonomous AI software engineer. With long-term reasoning and planning capabilities, Devin can execute complex engineering tasks and collaborate with users in real time. It empowers engineers to focus on more engaging problems and helps engineering teams achieve greater objectives.
Development and Tools
1.7M
Chinese Picks

Foxkit GPT AI Creation System
FoxKit GPT AI Creation System is a completely open-source system that supports independent secondary development. The system framework is developed using ThinkPHP6 + Vue-admin and provides application ends such as WeChat mini-programs, mobile H5, PC website, and official accounts. Sora video generation interface has been reserved. The system provides detailed installation and deployment documents, parameter configuration documents, and one free setup service.
Development and Tools
752.7K