%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Qwen2.5 1M
Overview :
Qwen2.5-1M is an open-source AI language model designed for long sequence tasks, with support for context lengths of up to 1 million tokens. Through innovative training methods and technical optimizations, it significantly enhances the performance and efficiency of long sequence processing. This model excels in long context tasks while maintaining strong performance in short text scenarios, making it an excellent open-source alternative among existing long context models. It is suitable for applications involving extensive text data, such as document analysis and information retrieval, providing developers with robust language processing capabilities.
Target Users :
This product is ideal for developers, researchers, and enterprises that handle long text data, particularly in fields such as natural language processing, text analysis, and information retrieval. It enables users to efficiently process large-scale text data, enhancing work productivity and model performance.
Use Cases
In long context tasks, such as needle-in-a-haystack scenarios, the model can accurately retrieve hidden information from 1 million token documents.
Demonstrates outstanding performance in complex long context understanding tasks like RULER, LV-Eval, and LongbenchChat.
Consistently outperforms GPT-4o-mini across multiple datasets, while handling eight times the context length.
Features
Supports a maximum context length of 1 million tokens, ideal for long sequence processing tasks.
Open-source model available in 7B and 14B versions for easy developer access.
Inference framework based on vLLM, integrating sparse attention methods, resulting in 3-7x speedup in inference.
Technical reports share insights on training and inference framework designs and results from ablation studies.
Online demos available on Hugging Face and Modelscope to experience the model's performance.
How to Use
1. Meet system requirements: Use a GPU with an optimized kernel, either from the Ampere or Hopper architecture, with CUDA version 12.1 or 12.3, and Python version >= 3.9 and <= 3.12.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Clone the vLLM repository and install the dependencies, cloning from a custom branch if needed and performing a manual installation.
3. Launch an OpenAI-compatible API service, configuring parameters based on your hardware setup, such as the number of GPUs and maximum input sequence length.
4. Interact with the model: Use Curl or Python code to send requests to the API and retrieve the model's response.






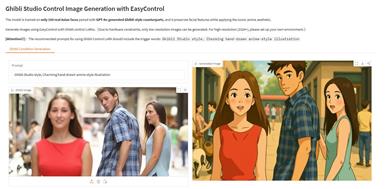





Featured AI Tools

Gemini
Gemini is the latest generation of AI system developed by Google DeepMind. It excels in multimodal reasoning, enabling seamless interaction between text, images, videos, audio, and code. Gemini surpasses previous models in language understanding, reasoning, mathematics, programming, and other fields, becoming one of the most powerful AI systems to date. It comes in three different scales to meet various needs from edge computing to cloud computing. Gemini can be widely applied in creative design, writing assistance, question answering, code generation, and more.
AI Model
11.4M
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M