%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Minimax Text 01
Overview :
MiniMax-Text-01 is a large language model developed by MiniMaxAI, boasting a total of 456 billion parameters, where each token activates 45.9 billion parameters. It employs a hybrid architecture that integrates lightning attention, softmax attention, and mixture of experts (MoE) techniques. Through advanced parallel strategies and innovative compute-communication overlap methods, such as Linear Attention Sequence Parallelism Plus (LASP+), variable-length circular attention, and Expert Tensor Parallelism (ETP), it expands the training context length to 1 million tokens and can handle up to 4 million tokens in inference. MiniMax-Text-01 has demonstrated top-tier model performance across multiple academic benchmark tests.
Target Users :
The target audience includes developers, researchers, and enterprise users who need to handle and generate long text content, such as professionals in natural language processing, content creators, educators, and others. The model's powerful language generation capabilities and ability to process long contexts enable it to meet their needs in various scenarios, including text generation, dialogue systems, content creation, and language translation.
Use Cases
Developers can utilize this model to create intelligent writing assistants that help users quickly generate articles, reports, and other content.
Researchers can use MiniMax-Text-01 for studies related to natural language processing, such as language understanding and text generation.
Enterprises can apply it in customer service to build intelligent customer support systems, providing more efficient and accurate client assistance.
Features
Powerful language generation capabilities that can produce high-quality text content.
Supports context processing of up to 4 million tokens, suitable for long text generation and understanding tasks.
Adopts a hybrid attention mechanism and mixture of experts technology to enhance model performance and efficiency.
Achieves large-scale parameter training through advanced parallel strategies and compute-communication overlap methods.
Excels in multiple academic benchmark tests, achieving top model performance.
How to Use
1. Load the model configuration and tokenizer from the Hugging Face website.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Set the quantization configuration; it is recommended to use int8 quantization.
3. Configure device mapping based on the number of devices, distributing different parts of the model across multiple GPUs.
4. Load the tokenizer and preprocess the input text.
5. Load the quantized model and move it to the specified device.
6. Set generation configurations such as the maximum number of new tokens and end token ID.
7. Use the model to generate text content and decode the generated IDs to obtain the final text output.






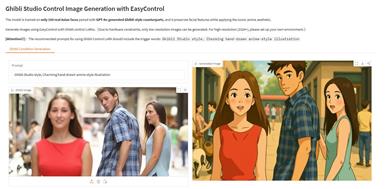





Featured AI Tools

Gemini
Gemini is the latest generation of AI system developed by Google DeepMind. It excels in multimodal reasoning, enabling seamless interaction between text, images, videos, audio, and code. Gemini surpasses previous models in language understanding, reasoning, mathematics, programming, and other fields, becoming one of the most powerful AI systems to date. It comes in three different scales to meet various needs from edge computing to cloud computing. Gemini can be widely applied in creative design, writing assistance, question answering, code generation, and more.
AI Model
11.4M
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M