%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

SPDL
Overview :
SPDL (Scalable and Performant Data Loading) is a new data loading solution developed by Meta Reality Labs, designed to enhance the efficiency of AI model training. Leveraging thread-based parallel processing, SPDL achieves high throughput in standard Python interpreters with lower resource consumption compared to traditional process-based solutions. It is compatible with Free-Threaded Python and offers higher throughput without GIL compared to FT Python implementations with GIL. Key advantages of SPDL include high throughput, comprehensible performance, no encapsulation of preprocessing operations, no introduction of domain-specific languages (DSL), seamless integration of asynchronous tools, flexibility, simplicity, and fault tolerance. The background highlights that as model sizes increase, so do computational demands for data; SPDL accelerates model training by maximizing GPU utilization.
Target Users :
The target audience includes researchers and machine learning engineers involved in AI model training. SPDL is ideal for them as it offers high-throughput data loading, reduces model training times, and decreases resource consumption, allowing for greater focus on model innovation and optimization.
Use Cases
Using SPDL to train a large image recognition model increased data loading speeds and reduced training times.
In training models for video and audio processing, SPDL significantly improved data loading efficiency by adjusting the concurrency of network transmission and video processing.
In a production environment, SPDL tripled data loading throughput and doubled the speed of model training.
Features
Framework agnosticism: As a data loading solution, SPDL does not rely on specific AI frameworks.
Multithreaded implementation: Utilizing Python's multithreading capabilities, SPDL achieves high throughput data loading.
Resource efficiency: Compared to traditional process methods, SPDL uses fewer computing resources.
Compatibility with Free-Threaded Python: Achieves higher performance with GIL disabled.
Flexible concurrency adjustment: Users can independently modify concurrency levels at each pipeline stage as needed.
Efficient media processing: SPDL implements basic media processing operations complementing parallel thread processing.
Asynchronous tool integration: SPDL seamlessly integrates asynchronous tools to enhance data loading performance.
Error tolerance and logging: SPDL can manage failures in network data retrieval and media data decoding.
How to Use
1. Build a data loading pipeline: Create a Pipeline object using the interfaces provided by SPDL, tailored to required data loading stages.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Specify concurrency: Assign different concurrency levels to each stage of the pipeline to optimize performance.
3. Utilize the pipeline: Once constructed, use the Pipeline object as an iterable for data loading.
4. Media processing: Leverage SPDL's media processing capabilities for decoding and preprocessing images or videos.
5. Data transfer: Directly transfer processed data to the GPU, avoiding additional memory copies.
6. Performance analysis: Analyze the performance of the SPDL data loading pipeline using tools like PyTorch profiler to identify bottlenecks.
7. Optimization adjustments: Based on performance analysis results, modify the concurrency levels and parameters of the pipeline to further enhance data loading efficiency.


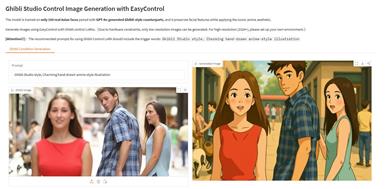







Featured AI Tools
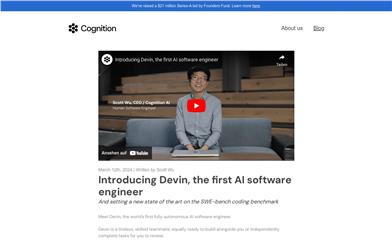
Devin
Devin is the world's first fully autonomous AI software engineer. With long-term reasoning and planning capabilities, Devin can execute complex engineering tasks and collaborate with users in real time. It empowers engineers to focus on more engaging problems and helps engineering teams achieve greater objectives.
Development and Tools
1.7M
Chinese Picks

Foxkit GPT AI Creation System
FoxKit GPT AI Creation System is a completely open-source system that supports independent secondary development. The system framework is developed using ThinkPHP6 + Vue-admin and provides application ends such as WeChat mini-programs, mobile H5, PC website, and official accounts. Sora video generation interface has been reserved. The system provides detailed installation and deployment documents, parameter configuration documents, and one free setup service.
Development and Tools
752.9K