%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
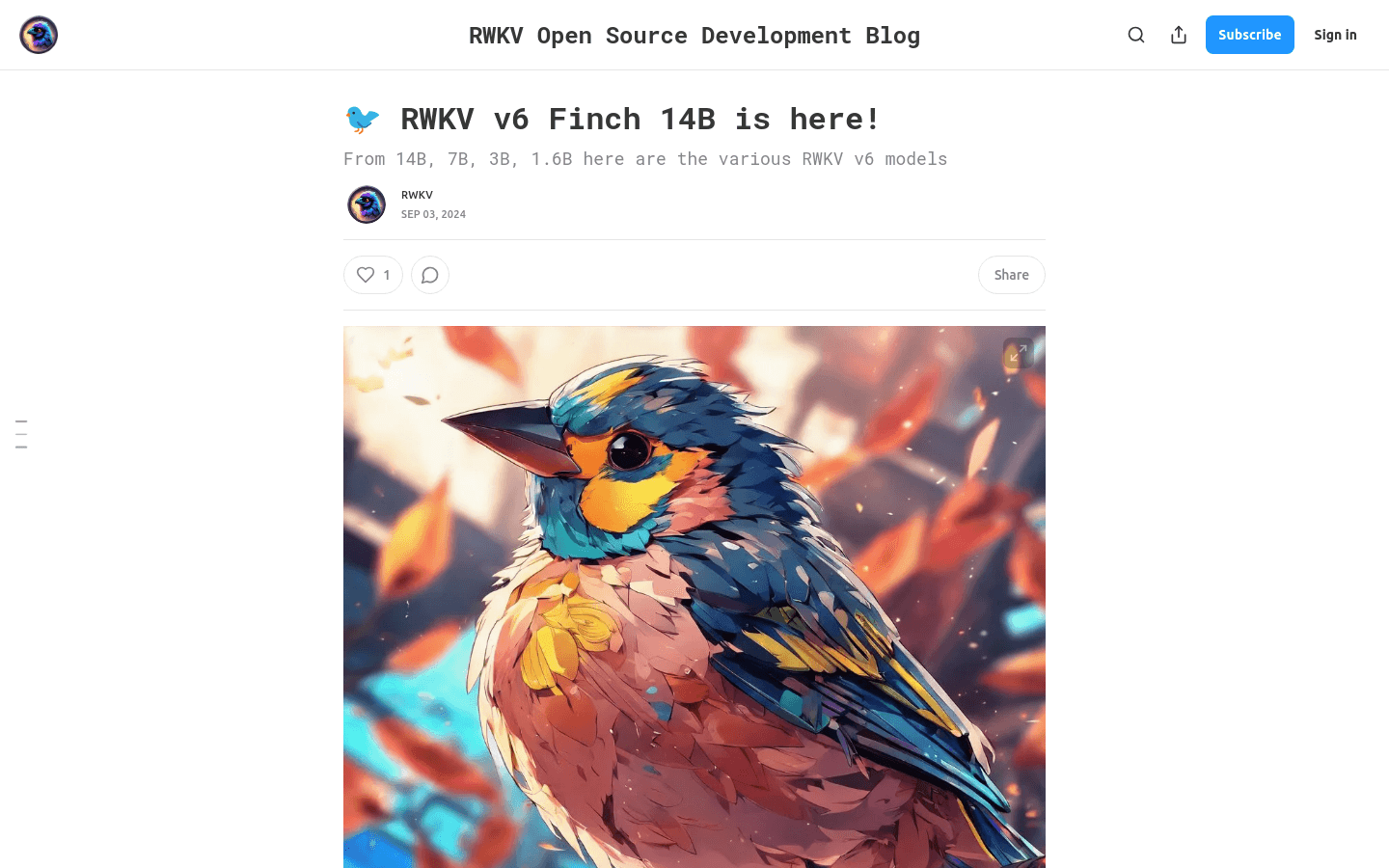
RWKV V6 Finch 14B
Overview :
RWKV v6 Finch 14B is the sixth version of the RWKV architecture and the largest model in the series. By introducing data dependencies into token shifts and time-mixing, it enhances efficiency in processing long texts. The Finch 14B model better manages its long-term memory when handling prompts, offering a broader range of applications. This model is open-source, recognized by the Linux Foundation, and accepts community contributions of GPU cluster time to support training efforts.
Target Users :
RWKV v6 Finch 14B is ideal for researchers and developers who need to handle large volumes of text data, especially in the fields of natural language processing and machine learning. Its efficiency and open-source nature make it a perfect choice for advancing AI research and applications.
Use Cases
For developing multilingual chatbots.
Conducting sentiment analysis on large-scale text datasets.
Assisting in translation and text generation tasks as a language model.
Features
The Finch 14B model features enhanced data processing capabilities with improved long-term memory management.
It continues the training based on the Eagle 7B model, stacking two 7B models to increase short-term memory.
Extensive benchmark testing has been conducted to assess model performance, including evaluations on the Open LLM Leaderboard v1.
Finch 7B improves upon Eagle 7B by 5.38% across all benchmarks, while Finch 14B adds an additional 7.14% improvement.
The model was trained on a dataset of 1.42 trillion tokens, demonstrating that its depth has not saturated.
The RWKV project receives donations of GPU cluster time to support further training and development.
Model weights, inference services, and training code are all open-source and available via the provided links.
How to Use
Visit the RWKV GitHub page to download the model weights and training code.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
Set up and configure the necessary hardware and software environment according to the provided guidelines.
Utilize the provided inference service for model testing or directly integrate it into applications.
Participate in community discussions and contribute GPU cluster time for the model's training and development.
Fine-tune and optimize the model based on project requirements.
Use the model for text processing tasks such as translation, summarization, or generation.


















Featured AI Tools

Gemini
Gemini is the latest generation of AI system developed by Google DeepMind. It excels in multimodal reasoning, enabling seamless interaction between text, images, videos, audio, and code. Gemini surpasses previous models in language understanding, reasoning, mathematics, programming, and other fields, becoming one of the most powerful AI systems to date. It comes in three different scales to meet various needs from edge computing to cloud computing. Gemini can be widely applied in creative design, writing assistance, question answering, code generation, and more.
AI Model
11.4M
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M