%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Vllm
Overview :
vLLM is a fast, easy-to-use, and efficient library for large language model (LLM) inference and service provision. By leveraging the latest service throughput technologies, efficient memory management, continuous batch processing requests, CUDA/HIP graph fast model execution, quantization techniques, and optimized CUDA kernels, it provides high-performance inference services. vLLM seamlessly integrates with popular HuggingFace models, supports various decoding algorithms including parallel sampling and beam search, supports tensor parallelism for distributed inference, supports streaming output, and is compatible with OpenAI API servers. Moreover, vLLM supports both NVIDIA and AMD GPUs, as well as experimental prefix caching and multi-lora support.
Target Users :
'vLLM's target audience is primarily developers and enterprises involved in large language model (LLM) inference and service provision. It is ideal for applications requiring fast and efficient deployment and execution of LLMs, such as natural language processing, machine translation, and text generation.
Use Cases
Deploy a chatbot using vLLM to provide natural language interaction services.
Integrate vLLM into a machine translation service to improve translation speed and efficiency.
Use vLLM for text generation tasks, such as automatically writing news articles or social media content.
Features
Seamless integration with HuggingFace models
High-throughput service provision with support for various decoding algorithms
Tensor parallelism support for distributed inference
Streaming output support for enhanced service efficiency
Compatibility with OpenAI API servers for easy integration with existing systems
Support for both NVIDIA and AMD GPUs for enhanced hardware compatibility
How to Use
1. Install the vLLM library and its dependencies.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Configure environment variables and usage statistics collection according to the documentation.
3. Select and integrate the desired model.
4. Configure decoding algorithms and performance tuning parameters.
5. Write code to implement the inference service, including request handling and response generation.
6. Deploy the vLLM service using Docker to ensure service stability and scalability.
7. Monitor production metrics and optimize service performance.


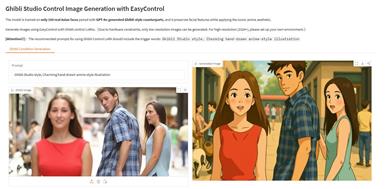







Featured AI Tools
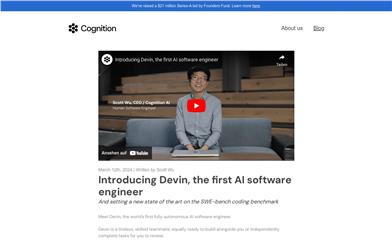
Devin
Devin is the world's first fully autonomous AI software engineer. With long-term reasoning and planning capabilities, Devin can execute complex engineering tasks and collaborate with users in real time. It empowers engineers to focus on more engaging problems and helps engineering teams achieve greater objectives.
Development and Tools
1.7M
Chinese Picks

Foxkit GPT AI Creation System
FoxKit GPT AI Creation System is a completely open-source system that supports independent secondary development. The system framework is developed using ThinkPHP6 + Vue-admin and provides application ends such as WeChat mini-programs, mobile H5, PC website, and official accounts. Sora video generation interface has been reserved. The system provides detailed installation and deployment documents, parameter configuration documents, and one free setup service.
Development and Tools
751.8K