%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
EN
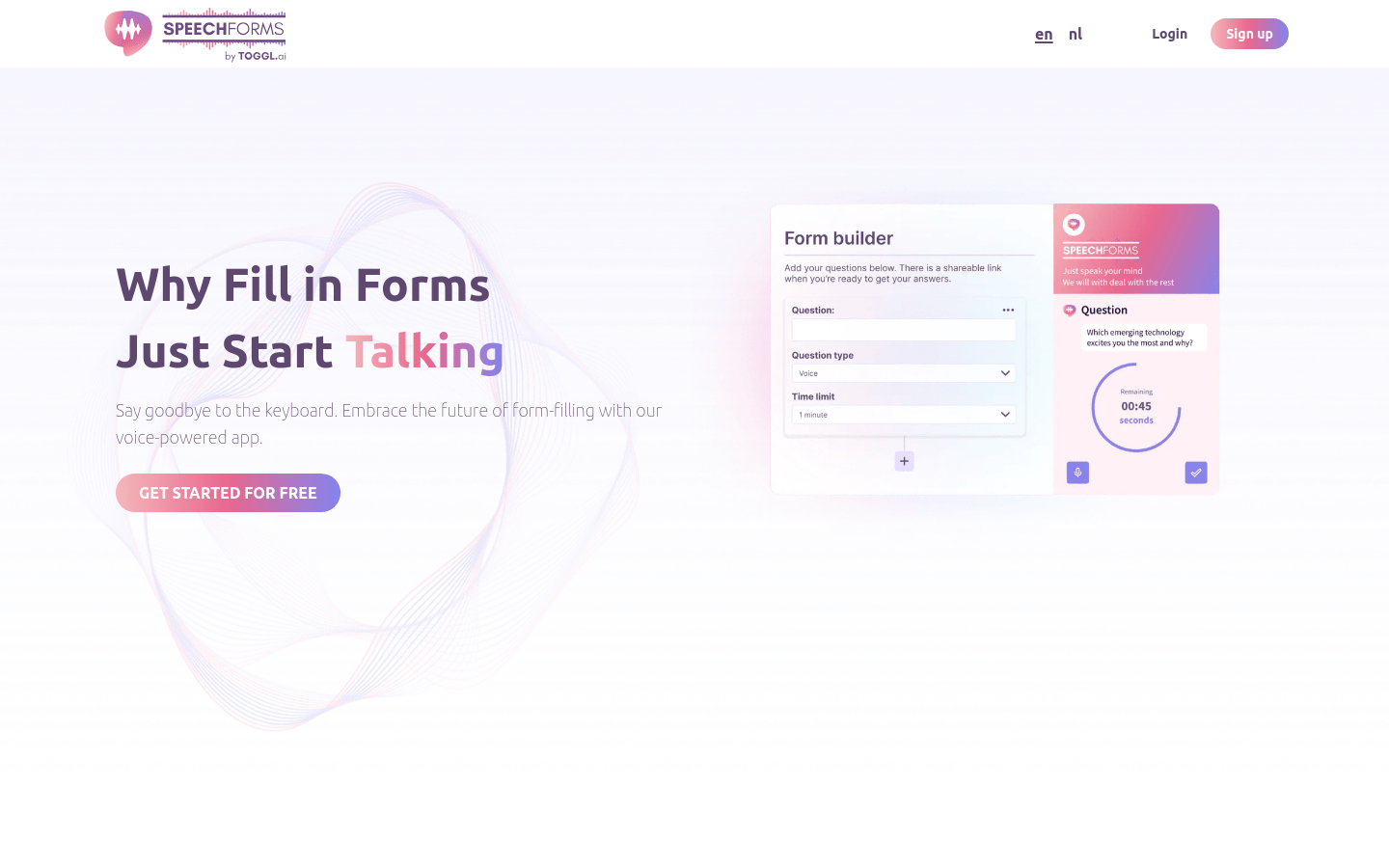
Speechforms
Overview :
Speechforms is an application that fills out forms using voice input. It allows users to ditch the keyboard and complete form filling in a more intuitive way, realizing the future of form filling. Speechforms offers a free trial, and specific pricing information can be found on the official website.
Target Users :
Speechforms is suitable for any scenario requiring form filling, whether personal or commercial.
Features
Fill out forms with voice input
Escape the keyboard for a more intuitive form-filling experience
Offer a free trial
Traffic Sources
| Direct Visits | 0.00% | External Links | 0.00% | 0.00% | |
| Organic Search | 0.00% | Social Media | 0.00% | Display Ads | 0.00% |
Latest Traffic Situation
| Monthly Visits | 0 |
| Average Visit Duration | 0.00 |
| Pages Per Visit | 0.00 |
| Bounce Rate | 0 |
Total Traffic Trend Chart
Similar Open Source Products

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition

Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition

Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
Social Auto Upload
This project aims to automate the uploading of videos to various social media platforms, including Douyin, Xiaohongshu, Video Account, TikTok, YouTube, and Bilibili. It provides rich features such as API encapsulation, Docker deployment, and multi-threaded uploads, allowing users to manage video content publishing more efficiently. This tool is ideal for content creators and enterprise users to achieve scheduled publishing and large-scale uploads, reducing labor costs.
Automated Workflow
Nanobrowser
Nanobrowser is an open-source Chrome extension designed for efficient web automation using AI technology. It supports multi-agent systems, allowing users to run complex web tasks using their own LLM API keys. Similar to OpenAI Operator, but completely free and open-source, users can run tasks within their local browser, ensuring privacy and security. Nanobrowser offers flexible LLM options, allowing users to choose different models based on their needs and assign different models to different agents, balancing performance and cost. Additionally, it features task automation, an interactive sidebar, session history, and more, making it suitable for users who require efficient web operations.
Automated Workflow
Automate
autoMate is an AI+RPA automation tool based on OmniParser, designed to achieve complex automation processes by describing tasks using natural language. It supports local deployment, protecting data security and privacy, while being able to automatically operate computer interfaces to complete complex workflows. This tool is mainly aimed at users who need to efficiently handle repetitive tasks, helping them save time and focus on more valuable work. This product is currently open-source on GitHub and is free for users.
Automated Workflow

Step Audio
Step-Audio is the first production-level open-source intelligent voice interaction framework, integrating voice understanding and generation capabilities. It supports multilingual dialogue, emotional intonation, dialects, speech rate, and prosodic style control. Its core technologies include a 130B parameter multimodal model, a generative data engine, fine-grained voice control, and enhanced intelligence. This framework promotes the development of intelligent voice interaction technology through open-source models and tools, and is suitable for a variety of voice application scenarios.
Speech Recognition

Fireredasr AED L
FireRedASR-AED-L is an open-source, industrial-grade automatic speech recognition model designed to meet the needs for high efficiency and performance in speech recognition. This model utilizes an attention-based encoder-decoder architecture and supports multiple languages including Mandarin, Chinese dialects, and English. It achieved new record levels in public Mandarin speech recognition benchmarks and has shown exceptional performance in singing lyric recognition. Key advantages of the model include high performance, low latency, and broad applicability across various speech interaction scenarios. Its open-source feature allows developers the freedom to use and modify the code, further advancing the development of speech recognition technology.
Speech Recognition
Fireredasr
FireRedASR is an open-source industrial-grade Mandarin automatic speech recognition model, utilizing an Encoder-Decoder and LLM integrated architecture. It includes two variants: FireRedASR-LLM and FireRedASR-AED, designed for high-performance and efficient needs respectively. The model excels in Mandarin benchmarking tests and also performs well in recognizing dialects and English speech. It is suitable for industrial applications requiring efficient speech-to-text conversion, such as smart assistants and video subtitle generation. The open-source model is easy for developers to integrate and optimize.
Speech Recognition
Alternatives
Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition
Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition

Amazon Nova Sonic
Amazon Nova Sonic is a cutting-edge foundational model that integrates speech understanding and generation, enhancing the natural fluency of human-computer dialogue. This model overcomes the complexities of traditional voice applications, achieving a deeper level of communication understanding through a unified architecture. It is suitable for AI applications across multiple industries and holds significant commercial value. As AI technology continues to develop, Nova Sonic will provide customers with better voice interaction experiences and improved service efficiency.
Speech Recognition
Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
Social Auto Upload
This project aims to automate the uploading of videos to various social media platforms, including Douyin, Xiaohongshu, Video Account, TikTok, YouTube, and Bilibili. It provides rich features such as API encapsulation, Docker deployment, and multi-threaded uploads, allowing users to manage video content publishing more efficiently. This tool is ideal for content creators and enterprise users to achieve scheduled publishing and large-scale uploads, reducing labor costs.
Automated Workflow
English Picks
Zapier MCP
Zapier MCP (Model Context Protocol) enables AI assistants to securely interact with over 8000 applications, simplifying the integration process with various services. This platform allows users to connect AI with real-world applications without writing complex API code, making it suitable for developers and business teams to quickly deploy AI automation. Zapier MCP is free for personal users, with basic usage limitations, ideal for quick starts and experimentation. The product primarily focuses on improving work efficiency by connecting AI with multiple tools to achieve more efficient workflows.
Automated Workflow
Windmill
Windmill is a platform focused on automated workflows, allowing users to create, run, and manage automated tasks through a visual interface. Its importance lies in its ability to significantly improve work efficiency and reduce repetitive manual labor. Key advantages include highly customizable automated workflows, a user-friendly interface, and powerful integration capabilities. The product background is the increasing demand for automated tools as enterprises undergo digital transformation. It is positioned as an enterprise-level automation solution; pricing is determined based on specific usage needs and functional modules, generally providing customized quotes.
Automated Workflow
Flowtest.ai
Flowtest.ai is an AI-powered website monitoring tool that detects website availability and performance issues by simulating real user behavior. It uses advanced AI technology to browse websites, perform actions like a real user, and monitor the website's operational status in real-time. Compared to traditional monitoring tools, Flowtest.ai's AI agent adapts to website changes, eliminating the need for frequent script maintenance, while providing instant alerts and detailed error reports to help users quickly locate and resolve issues. This product primarily targets e-commerce businesses, SaaS providers, and digital marketing agencies, aiming to help businesses reduce sales losses due to website malfunctions, improve user experience, and optimize website performance. Its pricing model is flexible, offering a free trial option suitable for businesses of all sizes.
Automated Workflow
Embra.ai
Embra is an innovative AI operating system designed for modern enterprises, aiming to integrate sales and product development processes through AI technology. It helps enterprise teams collaborate and manage projects more efficiently through features such as intelligent meeting minutes, task automation, and multilingual support. Embra's core strengths lie in its powerful graphical memory engine and AI agent capabilities, which automatically organize important information, generate reports, and support various work scenarios. Its pricing strategy is flexible, offering free trials and paid plans, suitable for enterprises pursuing efficient collaboration and digital transformation.
Automated Workflow
Featured AI Tools
Lugs.ai
Speech Recognition
599.5K
Chinese Picks
REECHO 睿声
REECHO.AI 睿声 is a hyper-realistic AI voice cloning platform. Users can upload voice samples, and the system utilizes deep learning technology to clone voices, generating high-quality AI voices. It allows for versatile voice style transformations for different characters. This platform provides services for voice creation and voice dubbing, enabling more people to participate in the creation of voice content through AI technology and lowering the barrier to entry. The platform is geared towards mass adoption and offers free basic functionality.
Speech Recognition
511.4K