%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
EN

Call Assistant
Overview :
Call Assistant is an AI assistant plugin developed by Anthropic, designed to automatically generate accurate textual records and summaries for call meetings, thereby improving team efficiency.
Target Users :
["Enhance sales call efficiency","Reduce manual note-taking","Analyze staff communication skills","Generate searchable call meeting transcripts"]
Use Cases
Sales teams use this plugin to automatically generate customer call records
Product managers utilize Call Assistant to analyze key points from user interviews
Project managers use the tool's summary feature to track meeting progress
Features
Automatically generate textual records of call meetings
Create content summaries for each call
Analyze the speaking time ratio of participants
Integrate with common video conferencing software
Traffic Sources
| Direct Visits | 59.74% | External Links | 34.46% | 0.06% | |
| Organic Search | 4.20% | Social Media | 1.17% | Display Ads | 0.38% |
Latest Traffic Situation
| Monthly Visits | 850.94k |
| Average Visit Duration | 825.36 |
| Pages Per Visit | 14.38 |
| Bounce Rate | 29.33% |
Total Traffic Trend Chart
Geographic Traffic Distribution
| Monthly Visits | 850.94k |
| United States | 29.91% |
| Germany | 8.87% |
| Spain | 6.26% |
| Canada | 5.68% |
| India | 4.91% |
Global Geographic Traffic Distribution Map
Similar Open Source Products

Orpheus TTS
Orpheus TTS is an open-source text-to-speech system based on the Llama-3b model, aiming to provide more natural human speech synthesis. It boasts strong voice cloning and emotional expression capabilities, suitable for various real-time applications. This product is free and aims to provide developers and researchers with a convenient speech synthesis tool.
Text to Speech

Spark TTS
Spark-TTS is a highly efficient text-to-speech synthesis model based on large language models, featuring single-stream decoupled speech tokens. Leveraging the power of large language models, it directly reconstructs audio predicted from code, omitting the additional acoustic feature generation model, thus improving efficiency and reducing complexity. This model supports zero-shot text-to-speech synthesis, enabling cross-lingual and code-switching scenarios, making it ideal for speech synthesis applications requiring high naturalness and accuracy. It also supports virtual voice creation; users can generate different voices by adjusting parameters such as gender, pitch, and speaking rate. The model aims to address the inefficiencies and complexities of traditional speech synthesis systems, providing a highly efficient, flexible, and powerful solution for research and production. Currently, the model is primarily intended for academic research and legitimate applications such as personalized speech synthesis, assistive technologies, and language research.
Text to Speech

Llasa
Llasa is a text-to-speech (TTS) base model based on the Llama framework, designed for large-scale speech synthesis tasks. The model is trained using 160,000 hours of tokenized speech data and has efficient language generation capabilities and multilingual support. Its main advantages include powerful speech synthesis capabilities, low inference costs, and flexible framework compatibility. This model is suitable for education, entertainment, and commercial scenarios, providing users with high-quality speech synthesis solutions. This model is currently freely available on Hugging Face, aiming to promote the development and application of speech synthesis technology.
Text to Speech

Indextts
IndexTTS is a GPT-style text-to-speech (TTS) model primarily developed based on XTTS and Tortoise. It can correct Chinese pronunciation using pinyin and control pauses using punctuation marks. This system introduces a character-pinyin mixed modeling method in Chinese scenarios, significantly improving training stability, timbre similarity, and audio quality. Furthermore, it integrates BigVGAN2 to optimize audio quality. The model is trained on tens of thousands of hours of data and outperforms current popular TTS systems such as XTTS, CosyVoice2, and F5-TTS. IndexTTS is suitable for scenarios requiring high-quality speech synthesis, such as voice assistants and audiobooks, and its open-source nature makes it suitable for academic research and commercial applications.
Text to Speech
Zonos
Zonos is an advanced text-to-speech model that supports multiple languages and can generate natural speech based on text prompts along with speaker embeddings or audio prefixes. It also features voice cloning, allowing for accurate replication of a speaker's voice with just a few seconds of reference audio. The model delivers high-quality speech output (44kHz) and allows fine control over speech rate, pitch variation, audio quality, and emotional tone (such as happiness, fear, sadness, and anger). Zonos offers Python and Gradio interfaces for easy user onboarding and supports deployment through Docker. The model achieves a real-time factor of approximately 2 times on an RTX 4090, making it suitable for applications that require high-quality speech synthesis.
Text to Speech
Zonos V0.1 Hybrid
Developed by Zyphra, Zonos-v0.1-hybrid is an open-source text-to-speech model capable of generating highly natural speech based on text prompts. The model is trained on extensive English voice data, employing eSpeak for text normalization and phoneme processing, and predicting DAC tokens via a transformer or hybrid backbone network. It supports multiple languages, including English, Japanese, Chinese, French, and German, and allows for fine control over speech speed, pitch, audio quality, and emotion. Additionally, it features zero-shot voice cloning, requiring only 5 to 30 seconds of speech samples to achieve high-fidelity voice replication. The model operates with a real-time factor of about 2x on an RTX 4090, offering fast performance. It is equipped with an easy-to-use gradio interface and can be easily installed and deployed using Docker. Currently, the model is available on Hugging Face for free, but users need to deploy it themselves.
Text to Speech
Llasa 1B
Llasa-1B is a text-to-speech model developed by the Audio Lab at the Hong Kong University of Science and Technology. Based on the LLaMA architecture and integrated with speech tokens from the XCodec2 codec, it converts text into natural and fluent speech. The model has been trained on 250,000 hours of Chinese and English speech data and supports generating speech from plain text, as well as utilizing given voice prompts for synthesis. Its main advantage is the ability to produce high-quality multilingual speech, making it suitable for various applications such as audiobooks and voice assistants. The model is licensed under CC BY-NC-ND 4.0, prohibiting commercial use.
Text to Speech
Llasa 3B
Llasa-3B is a powerful text-to-speech (TTS) model developed based on the LLaMA architecture, focused on Chinese and English speech synthesis. By integrating XCodec2's speech encoding technology, it efficiently converts text into natural and fluent speech. Its main advantages include high-quality speech output, support for multilingual synthesis, and flexible speech prompting capabilities. This model is suitable for various applications requiring speech synthesis, such as audiobook production and voice assistant development. Its open-source nature also allows developers to explore and expand its functionalities freely.
Text to Speech
Kokoro Onnx
kokoro-onnx is a text-to-speech (TTS) project based on the Kokoro model and ONNX runtime. It supports English and plans to support French, Japanese, Korean, and Chinese. The model offers near real-time performance on macOS M1 and provides a variety of voice options, including whispering. The model is lightweight, approximately 300MB (around 80MB when quantized). This project is open-source on GitHub under the MIT license, facilitating easy integration and use for developers.
Text to Speech
Alternatives
Ideately
Ideately is a collaborative platform offering seamless collaboration, intuitive guidance, and artificial intelligence features to drive innovation. Its key advantages include multiple brainstorming and strategy techniques, convenient automation, real-time voting decision-making, and AI-assisted analysis. The product is positioned to improve team creativity and decision-making efficiency.
Meeting Assistant
Schedo
Schedo is an AI-powered meeting scheduler that helps users simplify the appointment process, accept payments, and drive business growth. It offers personalized appointment pages, automated reminder features, and customer insights to help users manage appointments more intelligently and quickly.
Meeting Assistant

Live Portals | Custom Video Conferencing
Live & Interactive Video Conferencing is a powerful video conferencing platform that provides HD video and audio along with real-time features like chat, file sharing, and screen sharing. It supports custom branding, secure and controllable settings, real-time changes, and is suitable for various scenarios including sales, collaboration, and business presentations.
Meeting Assistant
Chinese Picks
Listenbrain AI
ListenBrain AI is a professional intelligent AI meeting assistant that provides one-stop intelligent meeting services aimed at improving meeting efficiency. It supports real-time meetings, meeting recording, and multilingual translation, and can automatically generate meeting minutes and summaries. This product is suitable for various types of meetings, including offline and online video conferences, and is an important tool for improving work efficiency.
Meeting Assistant
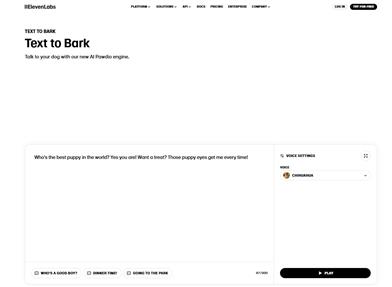
Text To Bark
Text to Bark is the first AI-powered text-to-speech model developed by ElevenLabs, designed to help people communicate more effectively with their dogs. This technology not only demonstrates high-quality speech synthesis but also simulates dog sounds naturally, creating a communication method suitable for dogs to understand. The launch of this innovative product elevates the interaction between humans and pets to a new level, making communication between owners and their dogs more interesting and effective. Users can generate corresponding "dog language" through simple text input, thereby better understanding and interacting with their pets.
Text to Speech
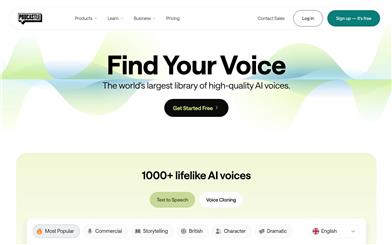
Podcastle AI Voices
This is a powerful text-to-speech generator with over 1000 high-quality AI voices. Suitable for various use cases such as podcasts, education, and business content creation. Users can leverage this platform to generate clear, natural-sounding voice content, supporting voice cloning and audio/video editing. Reasonably priced at only $39.99 per month, it's suitable for both individuals and businesses.
Text to Speech
Orpheus TTS
Orpheus TTS is an open-source text-to-speech system based on the Llama-3b model, aiming to provide more natural human speech synthesis. It boasts strong voice cloning and emotional expression capabilities, suitable for various real-time applications. This product is free and aims to provide developers and researchers with a convenient speech synthesis tool.
Text to Speech
Chinese Picks
Infie Thinker
Infie Thinker is an AIGC-powered visualized online collaboration space designed to provide enterprises and teams with a highly efficient digital platform for collaboration through features such as infinite canvas, audio and video conferencing, and mind mapping. It supports real-time and asynchronous collaboration and is suitable for various scenarios such as project management, brainstorming, and training. The product is positioned to improve team collaboration efficiency, promote knowledge sharing, and foster innovation. Currently, it offers free personal use and team trials; specific pricing can be found on the official website.
Meeting Assistant
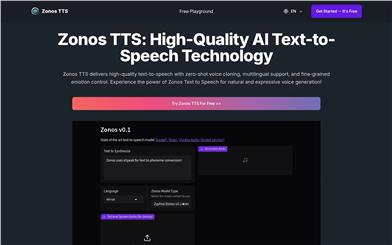
Zonos TTS
Zonos TTS is an advanced AI text-to-speech technology supporting multiple languages, emotion control, and zero-shot voice cloning. It generates natural, expressive speech suitable for various scenarios, including education, audiobooks, video games, and voice assistants. The technology provides users with an efficient and personalized speech generation solution through high-quality audio output (44kHz) and fast real-time processing capabilities. While not entirely free, it offers flexible pricing plans to meet the needs of different users.
Text to Speech
Featured AI Tools
Fresh Picks

Fish Audio Text To Speech
Text-to-speech technology converts textual information into speech, finding wide applications in assistive reading, voice assistants, and audiobook production. By mimicking human speech, it enhances the convenience of information access, particularly benefiting visually impaired individuals or those unable to read visually.
Text to Speech
8.7M
Elevenlabs
ElevenLabs is the most advanced text-to-speech and voice cloning software, capable of generating high-quality audio in any voice, style, and language you need. Whether you are a content creator or a novelist, our AI voice generator allows you to design captivating audio experiences. Elevate your content beyond words with our AI voice generator.
Text to Speech
2.3M