%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
EN

Speechmatics
Overview :
Speechmatics offers the most accurate AI voice technology, including AI transcription and real-time translation components. It can convert speech to text and provide real-time translation capabilities. Its accuracy and reliability make it the leading solution for speech transcription and translation. Speechmatics offers flexible pricing plans suitable for both individual and enterprise users.
Target Users :
Speechmatics has a wide range of applications, including meeting recordings, voice assistants, and voice translation.
Use Cases
Transcribe meeting recordings into text
Real-time translation of conference calls
Create voice assistant applications
Features
Speech Transcription
Real-time Translation
Traffic Sources
| Direct Visits | 38.72% | External Links | 47.92% | 0.13% | |
| Organic Search | 7.63% | Social Media | 4.96% | Display Ads | 0.63% |
Latest Traffic Situation
| Monthly Visits | 152.28k |
| Average Visit Duration | 97.05 |
| Pages Per Visit | 5.19 |
| Bounce Rate | 40.36% |
Total Traffic Trend Chart
Geographic Traffic Distribution
| Monthly Visits | 152.28k |
| United States | 17.56% |
| India | 6.23% |
| United Kingdom | 5.68% |
| Ecuador | 4.62% |
| Netherlands | 3.21% |
Global Geographic Traffic Distribution Map
Similar Open Source Products

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition

Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
Babeldoc
BabelDOC is a tool designed to simplify document translation, especially for PDF files. It offers not only a command-line interface but also a Python API and allows for self-deployment. Key advantages include free online translation services for up to 1000 pages, good compatibility, and extensibility. BabelDOC aims to be an embedded translation solution for various programs, suitable for academic research, business document translation, and more.
Translation

Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
Hugo Translator
hugo-translator is an article translation tool driven by a large language model (LLM). It can automatically translate articles from one language to another and generate new Markdown files. The tool supports OpenAI and DeepSeek models, allowing users to quickly complete translation tasks through simple configuration and commands. It is primarily aimed at users of the Hugo static website generator, helping them quickly implement the generation and management of multilingual content. The product is currently free and open-source, aiming to improve the efficiency of content creators and lower the threshold for multilingual content publishing.
Translation
Mtranserver
MTranServer is an offline translation server focusing on low resource consumption and fast response. Based on a highly efficient translation model and optimized backend architecture, it can achieve fast translation services on ordinary hardware. Its main advantages are low resource consumption (only 1GB of memory is required), no GPU support needed, and extremely fast translation speed, with an average response time of only 50ms per request. It is suitable for individual users and enterprises that need fast translation in a local environment, especially those with high requirements for privacy and data security. The product is completely free, supports multiple languages, and is an excellent, privately deployable alternative to Google Translate.
Translation
Firefox Translations Models
Firefox Translations Models is a set of CPU-optimized neural machine translation models developed by Mozilla, designed for the translation feature of the Firefox browser. The model provides fast and accurate translation services, supporting multiple language pairs, through efficient CPU acceleration technology. Its main advantages include high performance, low latency, and support for multiple languages. This model is the core technology of the Firefox browser's translation function, providing users with a seamless web translation experience.
Translation

Step Audio
Step-Audio is the first production-level open-source intelligent voice interaction framework, integrating voice understanding and generation capabilities. It supports multilingual dialogue, emotional intonation, dialects, speech rate, and prosodic style control. Its core technologies include a 130B parameter multimodal model, a generative data engine, fine-grained voice control, and enhanced intelligence. This framework promotes the development of intelligent voice interaction technology through open-source models and tools, and is suitable for a variety of voice application scenarios.
Speech Recognition

Fireredasr AED L
FireRedASR-AED-L is an open-source, industrial-grade automatic speech recognition model designed to meet the needs for high efficiency and performance in speech recognition. This model utilizes an attention-based encoder-decoder architecture and supports multiple languages including Mandarin, Chinese dialects, and English. It achieved new record levels in public Mandarin speech recognition benchmarks and has shown exceptional performance in singing lyric recognition. Key advantages of the model include high performance, low latency, and broad applicability across various speech interaction scenarios. Its open-source feature allows developers the freedom to use and modify the code, further advancing the development of speech recognition technology.
Speech Recognition
Alternatives
Bridgely
Bridgely is an AI-driven instant translation plugin that helps users overcome language barriers and make communication smoother. Its advantages include instant translation, 80% website coverage, AI technology support, etc. The product background information is detailed, focusing on improving cross-language communication efficiency.
Translation
AI Book Translate
AI Book Translate is a high-fidelity multi-pass AI translation tool that can complete the translation of an entire book in a few hours, almost reaching publication standards. It uses recursive refinement cycles to mimic the way human translators work, providing high-quality and cost-effective translation services for authors, editors, and small teams.
Translation
Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition
Ztalk.ai
Ztalk.ai is an innovative real-time voice translation tool that provides instant translation of more than 30 languages during video calls. It leverages advanced AI technology and seamless integration with various video conferencing platforms, aiming to enhance global team communication efficiency. The product offers different pricing plans to meet user needs, especially suitable for professional teams and enterprises requiring cross-language communication.
Translation
Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
Babeldoc
BabelDOC is a tool designed to simplify document translation, especially for PDF files. It offers not only a command-line interface but also a Python API and allows for self-deployment. Key advantages include free online translation services for up to 1000 pages, good compatibility, and extensibility. BabelDOC aims to be an embedded translation solution for various programs, suitable for academic research, business document translation, and more.
Translation

Amazon Nova Sonic
Amazon Nova Sonic is a cutting-edge foundational model that integrates speech understanding and generation, enhancing the natural fluency of human-computer dialogue. This model overcomes the complexities of traditional voice applications, achieving a deeper level of communication understanding through a unified architecture. It is suitable for AI applications across multiple industries and holds significant commercial value. As AI technology continues to develop, Nova Sonic will provide customers with better voice interaction experiences and improved service efficiency.
Speech Recognition
Krillin AI
Krillin AI is a powerful content creation service platform focused on audio and video localization and dubbing. It utilizes cutting-edge technology to improve the accuracy and quality of subtitles, suitable for multilingual needs in the global market. The platform supports translation in multiple languages, automatically filters out unnecessary filler words, and aims to provide a clear, professional subtitling experience. Krillin AI offers a free trial, allowing users to experience its powerful features.
Translation
Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
Featured AI Tools
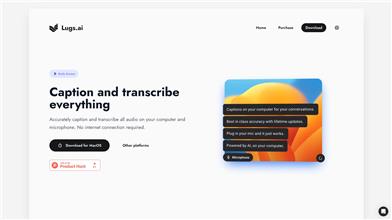
Lugs.ai
Speech Recognition
599.2K
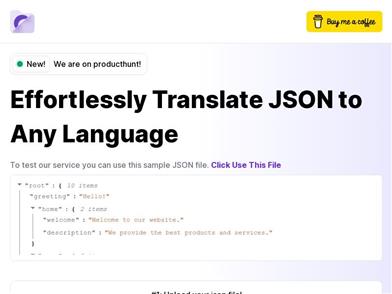
Transluna
Transluna is a powerful online tool designed to simplify the process of translating JSON files into multiple languages. It's an essential resource for developers, localization experts, and anyone involved in internationalization and localization. Transluna delivers accurate JSON translations, helping your website effectively communicate and resonate with global users.
Translation
552.3K