%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
EN

Dictation IO
Overview :
Dictation is a free online voice recognition software that allows you to input text via voice, helping you write emails, documents, and articles without typing.
Target Users :
Ideal for scenarios requiring voice input, such as writing emails, documents, etc.
Features
Voice input to text
Supports multiple languages
Ability to add paragraphs, punctuation, and emojis
Simple voice command operation
Traffic Sources
| Direct Visits | 46.40% | External Links | 45.57% | 0.08% | |
| Organic Search | 5.77% | Social Media | 1.86% | Display Ads | 0.32% |
Latest Traffic Situation
| Monthly Visits | 423.16k |
| Average Visit Duration | 49.17 |
| Pages Per Visit | 1.87 |
| Bounce Rate | 55.52% |
Total Traffic Trend Chart
Geographic Traffic Distribution
| Monthly Visits | 423.16k |
| United States | 21.70% |
| India | 16.78% |
| United Kingdom | 4.17% |
| Canada | 4.14% |
| Russia | 3.48% |
Global Geographic Traffic Distribution Map
Similar Open Source Products

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition

Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
English Picks
Dia AI
Dia is a text-to-speech (TTS) model developed by Nari Labs, featuring 160 million parameters, capable of generating highly realistic conversations directly from text. The model supports emotion and intonation control and can generate non-verbal communication such as laughter and coughs. Its pre-trained model weights are hosted on Hugging Face and are suitable for English generation. This product is crucial for research and educational purposes, enabling advancements in conversational AI technology.
Text-to-Speech

Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition

Step Audio
Step-Audio is the first production-level open-source intelligent voice interaction framework, integrating voice understanding and generation capabilities. It supports multilingual dialogue, emotional intonation, dialects, speech rate, and prosodic style control. Its core technologies include a 130B parameter multimodal model, a generative data engine, fine-grained voice control, and enhanced intelligence. This framework promotes the development of intelligent voice interaction technology through open-source models and tools, and is suitable for a variety of voice application scenarios.
Speech Recognition

Fireredasr AED L
FireRedASR-AED-L is an open-source, industrial-grade automatic speech recognition model designed to meet the needs for high efficiency and performance in speech recognition. This model utilizes an attention-based encoder-decoder architecture and supports multiple languages including Mandarin, Chinese dialects, and English. It achieved new record levels in public Mandarin speech recognition benchmarks and has shown exceptional performance in singing lyric recognition. Key advantages of the model include high performance, low latency, and broad applicability across various speech interaction scenarios. Its open-source feature allows developers the freedom to use and modify the code, further advancing the development of speech recognition technology.
Speech Recognition
Fireredasr
FireRedASR is an open-source industrial-grade Mandarin automatic speech recognition model, utilizing an Encoder-Decoder and LLM integrated architecture. It includes two variants: FireRedASR-LLM and FireRedASR-AED, designed for high-performance and efficient needs respectively. The model excels in Mandarin benchmarking tests and also performs well in recognizing dialects and English speech. It is suitable for industrial applications requiring efficient speech-to-text conversion, such as smart assistants and video subtitle generation. The open-source model is easy for developers to integrate and optimize.
Speech Recognition
Pengchengstarling
PengChengStarling is an open-source toolkit focused on multilingual automatic speech recognition (ASR), developed based on the icefall project. It supports the entire ASR process, including data processing, model training, inference, fine-tuning, and deployment. By optimizing parameter configurations and integrating language identifiers into the RNN-Transducer architecture, it significantly enhances the performance of multilingual ASR systems. Its main advantages include efficient multilingual support, a flexible configuration design, and robust inference performance. The models in PengChengStarling perform exceptionally well across various languages, require relatively small model sizes, and offer extremely fast inference speeds, making it suitable for scenarios that demand efficient speech recognition.
Speech Recognition
Realtimestt
RealtimeSTT is an open-source speech recognition model capable of converting spoken language into text in real time. It employs advanced voice activity detection technology to automatically detect the start and end of speech without manual intervention. Additionally, it supports wake word activation, allowing users to initiate speech recognition by saying specific wake words. The model is characterized by low latency and high efficiency, making it suitable for real-time transcription applications such as voice assistants and meeting notes. It is developed in Python, easy to integrate and use, and is open-source on GitHub, with an active community that continuously provides updates and improvements.
Speech Recognition
Alternatives
Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 is a 600 million parameter automatic speech recognition (ASR) model designed to achieve high-quality English transcription with accurate timestamp prediction and automatic punctuation and capitalization support. The model is based on the FastConformer architecture, capable of efficiently processing audio clips up to 24 minutes long, making it suitable for developers, researchers, and various industry applications.
Speech Recognition
Kimi Audio
Kimi-Audio is an advanced open-source audio foundation model designed to handle a variety of audio processing tasks, such as speech recognition and audio dialogue. The model has been extensively pre-trained on over 13 million hours of diverse audio and text data, giving it strong audio reasoning and language understanding capabilities. Its key advantages include excellent performance and flexibility, making it suitable for researchers and developers to conduct audio-related research and development.
Speech Recognition
English Picks
Dia AI
Dia is a text-to-speech (TTS) model developed by Nari Labs, featuring 160 million parameters, capable of generating highly realistic conversations directly from text. The model supports emotion and intonation control and can generate non-verbal communication such as laughter and coughs. Its pre-trained model weights are hosted on Hugging Face and are suitable for English generation. This product is crucial for research and educational purposes, enabling advancements in conversational AI technology.
Text-to-Speech

Amazon Nova Sonic
Amazon Nova Sonic is a cutting-edge foundational model that integrates speech understanding and generation, enhancing the natural fluency of human-computer dialogue. This model overcomes the complexities of traditional voice applications, achieving a deeper level of communication understanding through a unified architecture. It is suitable for AI applications across multiple industries and holds significant commercial value. As AI technology continues to develop, Nova Sonic will provide customers with better voice interaction experiences and improved service efficiency.
Speech Recognition
Megatts 3
MegaTTS 3 is a highly efficient speech synthesis model based on PyTorch, developed by ByteDance, with ultra-high-quality speech cloning capabilities. Its lightweight architecture contains only 0.45B parameters, supports Chinese, English, and code switching, and can generate natural and fluent speech from input text. It is widely used in academic research and technological development.
Speech Recognition
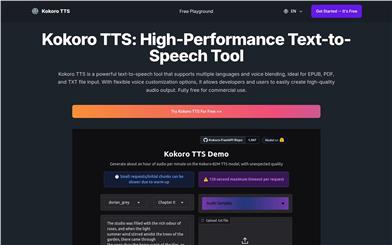
Kokorotts
Kokoro TTS is a powerful text-to-speech tool that supports multiple languages and voice blending features, capable of converting EPUB, PDF, and TXT files into high-quality speech output. The tool provides developers and users with flexible voice customization options to easily create professional-grade audio. Its main advantages include multilingual support, voice blending, flexible input formats, and a free commercial license. This product is positioned to provide creators, developers, and businesses with an efficient and low-cost speech synthesis solution, suitable for audiobook creation, video narration, podcast production, educational content generation, and customer service, among other scenarios.
Text-to-Speech
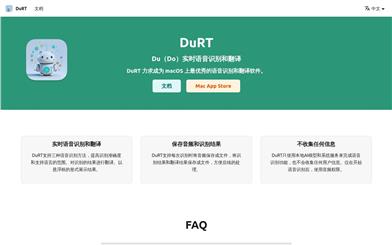
Durt
DuRT is a speech recognition and translation tool focusing on macOS. It uses local AI models and system services to achieve real-time speech recognition and translation, supporting multiple speech recognition methods to improve accuracy and language support. The product displays results in a floating window for easy access during use. Its main advantages include high accuracy, privacy protection (no user information is collected), and a convenient user experience. DuRT is positioned as a highly efficient productivity tool, designed to help users communicate and work more efficiently in multilingual environments. The product is currently available on the Mac App Store; pricing is not explicitly mentioned on the page.
Speech Recognition
Elevenlabs Scribe
Scribe is a high-accuracy speech-to-text model developed by ElevenLabs, designed to handle the unpredictability of real-world audio. It supports 99 languages and provides features such as word-level timestamps, speaker diarization, and audio event labeling. Scribe demonstrates superior performance on the FLEURS and Common Voice benchmarks, surpassing leading models like Gemini 2.0 Flash, Whisper Large V3, and Deepgram Nova-3. It significantly reduces error rates for traditionally underserved languages (such as Serbian, Cantonese, and Malayalam), where error rates often exceed 40% in competing models. Scribe offers an API for developer integration and will launch a low-latency version to support real-time applications.
Speech Recognition
Supertone Play
Supertone Play is a platform dedicated to voice cloning and AI voice content creation. Leveraging advanced AI technology, it empowers users to create personalized voice content through simple voice inputs. This technology has wide-ranging applications in entertainment, education, business, and more, providing users with a novel means of expression and creation. The platform's voice cloning feature allows users to rapidly create unique voice models, while AI voice content creation generates high-quality voice content based on user requirements. The key advantages of this technology are its efficiency, personalization, and innovative nature, catering to diverse user needs in voice creation.
Speech Recognition
Featured AI Tools
Lugs.ai
Speech Recognition
599.2K
Chinese Picks
REECHO 睿声
REECHO.AI 睿声 is a hyper-realistic AI voice cloning platform. Users can upload voice samples, and the system utilizes deep learning technology to clone voices, generating high-quality AI voices. It allows for versatile voice style transformations for different characters. This platform provides services for voice creation and voice dubbing, enabling more people to participate in the creation of voice content through AI technology and lowering the barrier to entry. The platform is geared towards mass adoption and offers free basic functionality.
Speech Recognition
511.2K