%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Mann E Art
Overview :
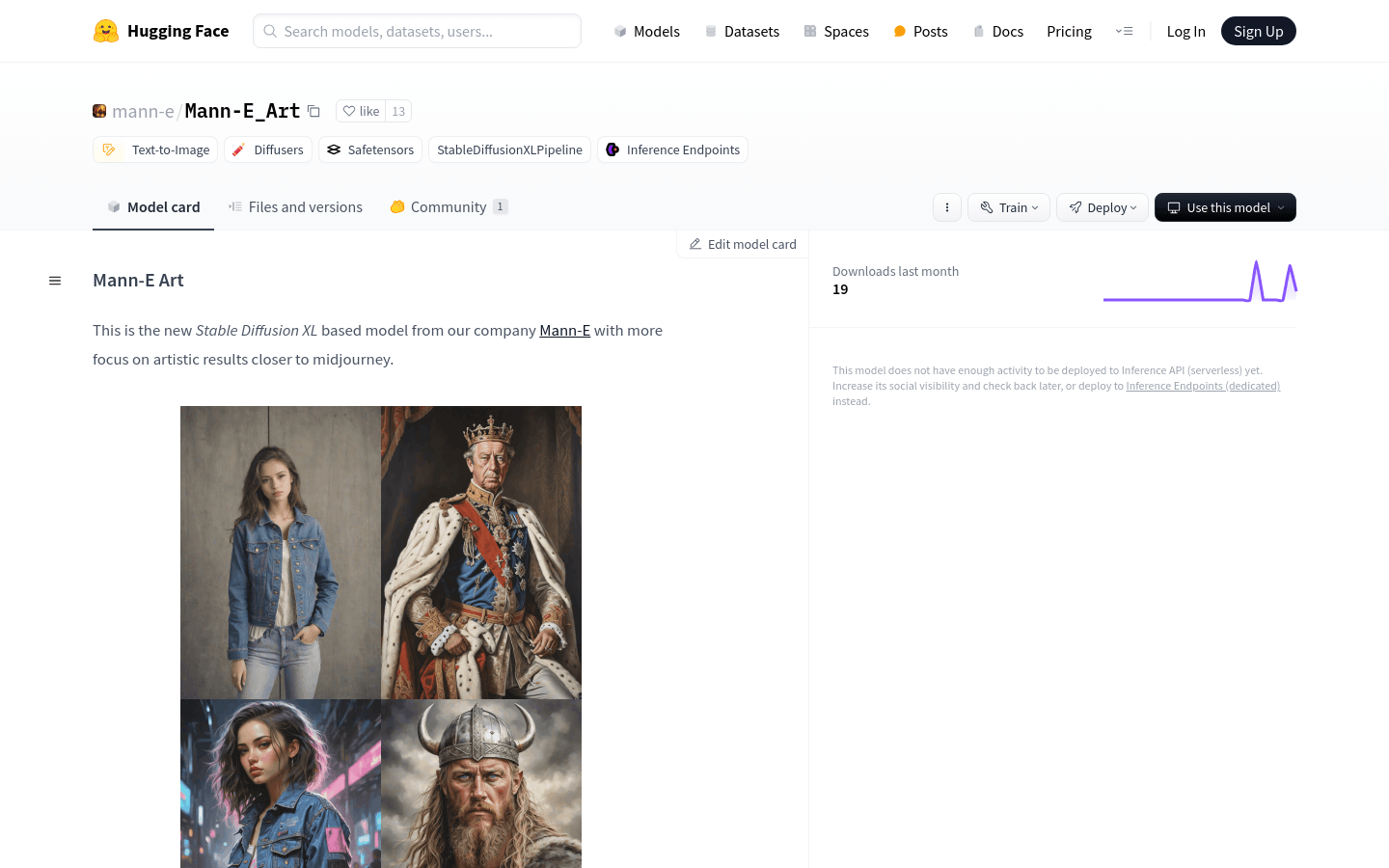
Mann-E Art is an image generation model developed by Mann-E that is based on Stable Diffusion XL, focusing on creating images similar to the midjourney art style. The model utilizes approximately 1,000 midjourney outputs along with photos collected by the team during training. It excels at generating photographs, artworks, and digital paintings but may perform average in pixel art or vector illustrations.
Target Users :
The Mann-E Art model is suitable for designers and artists who need to generate high-quality artistic images, as well as researchers and developers interested in image generation technology. It helps users quickly create artful images and enhances creative efficiency.
Use Cases
Designers use Mann-E Art to create cat illustrations with a Middle Eastern style
Artists leverage the model to produce digital paintings
Researchers employ Mann-E Art for studies in AI art generation technologies
Features
Generate realistic images of cats in Middle Eastern cities
Supports image generation using DiffusionPipeline
Utilizes DPMSolverSinglestepScheduler for single-step scheduling
Allows customization of the number of inference steps for image generation
Adjustable guidance scale for controlling the details in generated images
Supports generating images at a resolution of 768x768
Enables generation of larger resolutions such as 1024x1024
Provides good support for rectangular images like 832x1216 and 608x1080
How to Use
Import DiffusionPipeline and DPMSolverSinglestepScheduler
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
Load the Mann-E Art model from a pre-trained model
Set the model to run on a CUDA device to utilize GPU acceleration
Configure the DPMSolverSinglestepScheduler to use Karras' sigma values
Define the theme of the generated image using the prompt parameter
Set the num_inference_steps and guidance_scale parameters
Specify the width and height of the image
Call the model to generate the image and save it to a local file














Featured AI Tools
Chinese Picks

Capcut Dreamina
CapCut Dreamina is an AIGC tool under Douyin. Users can generate creative images based on text content, supporting image resizing, aspect ratio adjustment, and template type selection. It will be used for content creation in Douyin's text or short videos in the future to enrich Douyin's AI creation content library.
AI image generation
9.0M

Outfit Anyone
Outfit Anyone is an ultra-high quality virtual try-on product that allows users to try different fashion styles without physically trying on clothes. Using a two-stream conditional diffusion model, Outfit Anyone can flexibly handle clothing deformation, generating more realistic results. It boasts extensibility, allowing adjustments for poses and body shapes, making it suitable for images ranging from anime characters to real people. Outfit Anyone's performance across various scenarios highlights its practicality and readiness for real-world applications.
AI image generation
5.3M