%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
AI ASMR
AI ASMR Generator是一款利用AI技术生成ASMR视频的工具。它可以帮助用户快速创建高质量的ASMR视频,提供更丰富的体验和刺激。
视频生成
50.8K
Echovox Studio
Echovox Studio是一款功能强大的音乐制作软件,拥有先进的录音和混音功能,可用于制作各种音乐类型。它的主要优点在于直观易用的界面和丰富的音频处理工具。
音乐生成
45.5K
Audio SDS
Audio-SDS 是一个将 Score Distillation Sampling(SDS)概念应用于音频扩散模型的框架。该技术能够在不需要专门数据集的情况下,利用大型预训练模型进行多种音频任务,如物理引导的冲击声合成和基于提示的源分离。其主要优点在于通过一系列迭代优化,使得复杂的音频生成任务变得更为高效。此技术具有广泛的应用前景,能够为未来的音频生成和处理研究提供坚实基础。
音频生成
44.2K

Kimi Audio
Kimi-Audio 是一个先进的开源音频基础模型,旨在处理多种音频处理任务,如语音识别和音频对话。该模型在超过 1300 万小时的多样化音频数据和文本数据上进行了大规模预训练,具有强大的音频推理和语言理解能力。它的主要优点包括优秀的性能和灵活性,适合研究人员和开发者进行音频相关的研究与开发。
语音识别
80.3K
Unifab
UniFab 是一款强大的 AI 助力的视频音频增强工具。它利用先进的超分辨率技术,能够将视频分辨率提升至 8K/16K,同时将 SDR 转换为 HDR,为用户提供影院级的视觉体验。其 AI 驱动的深度学习能够智能分析并优化每一帧画面,呈现出鲜艳的色彩、逼真的细节和清晰的视觉效果。此外,UniFab 还支持音频上混功能,可将音频轨道升级为 EAC3 5.1/DTS 7.1 环绕声,让用户沉浸在电影般的听觉享受中。该产品主要面向摄影师、影视爱好者、视频创作者等群体,帮助他们优化视频内容,提升创作质量。
视频编辑
63.8K
Inspiremusic
InspireMusic 是一个专注于音乐、歌曲和音频生成的 AIGC 工具包和模型框架,采用 PyTorch 开发。它通过音频标记化和解码过程,结合自回归 Transformer 和条件流匹配模型,实现高质量音乐生成。该工具包支持文本提示、音乐风格、结构等多种条件控制,能够生成 24kHz 和 48kHz 的高质量音频,并支持长音频生成。此外,它还提供了方便的微调和推理脚本,方便用户根据需求调整模型。InspireMusic 的开源旨在赋能普通用户通过音乐创作提升研究中的音效表现。
音乐生成
108.5K
Aivocal
AIVocal是一款基于人工智能技术的在线人声消除工具,它能够在短时间内从任何歌曲中去除人声,创建伴奏带、分离乐器音轨,并提升音乐制作效率。该产品以其高效率、高精度和易用性,满足了音乐制作人、内容创作者和翻唱艺术家的需求。AIVocal支持多种音频格式,如MP3、WAV和FLAC,适合专业音乐制作和日常娱乐使用。
音频生成
60.7K
优质新品
Omniaudio 2.6B
OmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个自定义投影模块,与传统的将ASR和LLM模型串联的方法不同,它将这两种能力统一在一个高效的架构中,以最小的延迟和资源开销实现。这使得它能够安全、快速地在智能手机、笔记本电脑和机器人等边缘设备上直接处理音频文本。
语音识别
61.5K
Comfyui MMAudio
ComfyUI-MMAudio是一个基于ComfyUI的插件,它允许用户利用MMAudio模型进行音频处理。该插件的主要优点在于能够提供高质量的音频生成和处理能力,支持多种音频模型,并且易于集成到现有的音频处理流程中。产品背景信息显示,它是由kijai开发的,并且是开源的,可以在GitHub上找到。目前,该插件主要面向技术爱好者和音频处理专业人士,可以免费使用。
音频生成
75.1K
Auralis
Auralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高速、高效、易集成和高质量的音频输出为主要优点,适用于需要快速文本到语音转换的场景。Auralis基于Python API,支持长文本流式处理、内置音频增强、自动语言检测等功能。产品背景信息显示,Auralis由AstraMind AI开发,旨在提供一种实用于现实世界应用的文本到语音解决方案。产品价格未在页面上明确标注,但代码库在Apache 2.0许可下发布,可以免费用于项目中。
文本转声音
84.2K
Songcleaner
SongCleaner是一个利用人工智能技术来清理歌曲中不适当词汇的平台,它允许用户上传MP3或WAV格式的音频文件,然后通过AI分析和编辑,生成适合所有年龄段的清洁版本和伴奏音轨。这项技术的重要性在于它能够使音乐内容更加适合公共播放和家庭环境,同时保持音乐的原始魅力。SongCleaner以其快速、免费和用户友好的特点,为用户提供了一个便捷的解决方案,以满足对清洁音乐内容的需求。
音频生成
130.3K
国外精选

Suno V4
Suno v4是一个音乐创作平台,它通过提供更清晰的音频、更锐利的歌词和更动态的歌曲结构,帮助用户以更快的速度创作音乐。这个平台不仅提升了音乐创作的质量,还通过引入新的功能和技术,如ReMi歌词辅助模型和个性化封面艺术,进一步增强了用户的创作体验。Suno v4的背景是音乐创作领域对于更高效、更高质量的创作工具的需求,它通过技术的进步来满足这一需求。Suno v4目前处于Beta测试阶段,主要面向Pro和Premier用户。
音乐生成
70.4K
Outetts 0.1 350M
OuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合成。该模型基于LLaMa架构,使用350M参数,展示了直接使用语言模型进行语音合成的潜力。它通过三个步骤处理音频:使用WavTokenizer进行音频标记化、CTC强制对齐创建精确的单词到音频标记映射、以及遵循特定格式的结构化提示创建。OuteTTS的主要优点包括纯语言建模方法、声音克隆能力、与llama.cpp和GGUF格式的兼容性。
文本转声音
75.3K

Hertz Dev
hertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术,能够将单声道16kHz语音转换为8Hz潜在表示,具有1kbps的比特率,性能优于其他音频编码器。hertz-dev的主要优点包括低延迟、高效率和易于研究人员进行微调和构建。产品背景信息显示,Standard Intelligence致力于构建对全人类有益的通用智能,而hertz-dev是这一旅程的第一步。
模型训练与部署
60.2K
Fish Agent V0.1 3B
Fish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统语义编码器/解码器的需求。此外,它还是一个尖端的文本到语音(TTS)模型,训练数据涵盖了700,000小时的多语言音频内容。作为Qwen-2.5-3B-Instruct的继续预训练版本,它在200B语音和文本标记上进行了训练。该模型支持包括英语、中文在内的8种语言,每种语言的训练数据量不同,其中英语和中文各约300,000小时,其他语言各约20,000小时。
文本转声音
54.1K
Browser AI Kit
Browser AI Kit是一个集成了多种AI工具的平台,用户可以在浏览器中直接使用这些工具,无需安装或设置。它提供了音频转文本、去除背景、文本转语音等多种功能,并且完全免费。这个工具箱基于Transformers.js开发,强调数据安全和隐私保护,所有数据处理都在本地进行,不上传任何服务器。它的目标是为用户提供一个便捷、安全、多功能的AI工具平台。
开发与工具
52.2K
Universal 2
Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复杂性,为用户提供无需二次检查的音频数据。这一技术的重要性在于它能够为产品体验提供更敏锐的洞察力、更快的工作流程和一流的产品体验。Universal-2在专有名词识别、文本格式化和字母数字识别方面都有显著提升,减少了实际应用中的词错误率。
语音识别
51.6K
Diarizen
DiariZen是一个基于AudioZen和Pyannote 3.1驱动的说话人分割工具包。说话人分割是音频处理中的一个关键步骤,它能够将一段音频中的不同说话人进行区分。这项技术在会议记录、电话监控、安全监听等多个领域都有广泛的应用。DiariZen的主要优点包括易于使用、高准确性和开源,使得研究人员和开发者可以自由地使用和改进它。DiariZen在GitHub上以MIT许可证发布,这意味着它是完全免费的,并且可以被商业使用。
开发与工具
64.3K
AILIBRI
AILIBRI是一个汇集了超过2000个AI神经网络工具的目录网站,涵盖了文本、图像、视频、音频等多个领域的工具。它为用户寻找合适的AI工具提供了极大的便利,无论是专业人士还是初学者,都能在这里找到满足其需求的工具。该网站提供了详细的分类和搜索功能,帮助用户快速定位到所需的工具。
AI信息平台
64.6K
Ezaudio
EzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声音效果生成。
AI文本转语音
56.3K

Seed Vc
seed-vc 是一个基于 SEED-TTS 架构的声音转换模型,能够实现零样本的声音转换,即无需特定人的声音样本即可转换声音。该技术在音频质量和音色相似性方面表现出色,具有很高的研究和应用价值。
AI语音合成
102.1K
Easy Voice Toolkit
Easy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完整的工作流程,用户可以根据需要选择性使用这些工具,或按顺序使用,逐步将原始音频文件转换为理想的语音模型。
AI音频编辑
102.7K
优质新品
Audio Chat
Audio Chat是一个专注于音频文件处理的网站,它允许用户上传讲座、会议或面试等音频文件,并进行对话分析。该产品通过先进的音频处理技术,帮助用户快速获取对话内容的要点,提高学习和工作效率。
语音识别
67.1K
优质新品
Qwen2 Audio
Qwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交互模式:语音聊天和音频分析。它在13个标准基准测试中表现出色,包括自动语音识别、语音到文本翻译、语音情感识别等。
AI语音助手
211.4K
Elevenlabs Audio Isolation API
Audio Isolation 是 ElevenLabs 提供的一项在线音频处理服务,专注于从音频中分离出人声或背景音乐。这项技术在音乐制作、视频后期制作等领域具有重要应用价值,能够显著提高音频编辑的效率和质量。产品通过 API 提供服务,支持多种编程语言的调用,具有高度的灵活性和便捷性。定价方面,API 按照处理的音频字符数每分钟收费,具体价格未在页面上明确标注。
AI音频编辑
73.1K
DETECT 2B
DETECT-2B 是 Resemble AI 的最新深度伪 造检测解决方案。它能够以高达 94% 以上的准确率在 200 毫秒内检测 30 多种语言。通过我们高效且多语言的技术,有效应对基于 AI 生成的音频欺诈。
AI检测
99.1K
优质新品
Stable Audio Open 1.0
Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文本提示生成音乐和音频,支持研究和实验,以探索生成性AI模型的当前能力。该模型在Freesound和Free Music Archive (FMA)的数据集上进行训练,确保了数据的多样性和版权合法性。
AI音乐生成
82.2K
优质新品
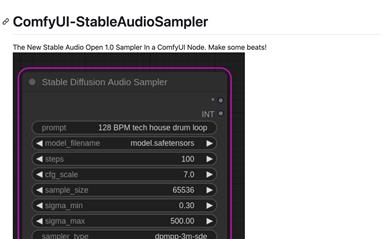
Comfyui StableAudioSampler
ComfyUI-StableAudioSampler 是一款集成在 ComfyUI 节点中的音频采样器插件,它允许用户生成音频并输出原始字节和采样率,支持所有原始 Stable Audio Open 参数,并可以保存音频到文件。这个插件是开源的,并且正在积极开发中,旨在为音乐制作者提供一个易于使用且功能强大的工具。
AI音乐生成
93.8K

Spleetergui
SpleeterGUI 是一个音乐源分离的桌面应用程序,用户无需安装 Python 或 Spleeter,该应用程序内含预装 Python 版本和 Spleeter。通过分离音轨,用户可以从音乐中提取出不同的声音源,提供了更灵活的音频处理能力。
音频生成
104.1K
中文精选
MVSEP
MVSEP是一款在线音频处理工具,利用先进的音频分离技术可将音乐和语音从音频文件中分离出来,适用于音乐制作、音频编辑、广播、电影后期制作等领域。优点包括高质量的音频输出、快速的处理速度和用户友好的操作界面。提供不同模型选择。
音频生成
154.3K
- 1
- 2
- 3
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.2K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.2K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
82.8K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.1K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
78.4K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
650.5K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M