%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Blackwave
BlackWave是一个人工智能图像生成工具,利用神经网络技术快速、轻松、免费生成独特图像。产品背景是基于先进的图像生成算法,定位于为用户提供高效、便捷的图像生成服务。
神经网络
39.5K
Procyon AI Computer Vision Benchmark
Procyon AI Computer Vision Benchmark是由UL Solutions开发的一款专业基准测试工具,旨在帮助用户评估不同AI推理引擎在Windows PC或Apple Mac上的性能表现。该工具通过执行一系列基于常见机器视觉任务的测试,利用多种先进的神经网络模型,为工程团队提供独立、标准化的评估手段,以便他们了解AI推理引擎的实施质量和专用硬件的性能。产品支持多种主流的AI推理引擎,如NVIDIA® TensorRT™、Intel® OpenVINO™等,并可比较浮点和整数优化模型的性能。其主要优点包括易于安装和运行、无需复杂配置、可导出详细结果文件等。产品定位为专业用户,如硬件制造商、软件开发者和科研人员,以助力他们在AI领域的研发和优化工作。
开发与工具
49.1K
国外精选
Large Geospatial Model
Niantic的Large Geospatial Model (LGM) 是一个先锋概念,旨在通过大规模机器学习理解场景并将其与全球数百万其他场景连接起来。LGM不仅使计算机能够感知和理解物理空间,还能以新的方式与它们互动,成为AR眼镜及更广泛领域(包括机器人技术、内容创作和自主系统)的关键组成部分。随着我们从手机转向与现实世界相连的可穿戴技术,空间智能将成为世界未来的操作系统。
机器学习
51.6K

HOVER
HOVER是一个针对人形机器人的多功能神经全身控制器,它通过模仿全身运动来提供通用的运动技能,学习多种全身控制模式。HOVER通过多模式策略蒸馏框架将不同的控制模式整合到一个统一的策略中,实现了在不同控制模式之间的无缝切换,同时保留了每种模式的独特优势。这种控制器提高了人形机器人在多种模式下的控制效率和灵活性,为未来的机器人应用提供了一个健壮且可扩展的解决方案。
开发与工具
50.0K
Multispecies Whale Detection
multispecies-whale-detection 是谷歌开发的一个开源项目,旨在通过神经网络检测和分类不同物种和地理区域的鲸鱼声音。这个工具可以帮助研究人员和环保组织更好地理解和保护海洋生物多样性。
AI音频编辑
46.9K
AILIBRI
AILIBRI是一个汇集了超过2000个AI神经网络工具的目录网站,涵盖了文本、图像、视频、音频等多个领域的工具。它为用户寻找合适的AI工具提供了极大的便利,无论是专业人士还是初学者,都能在这里找到满足其需求的工具。该网站提供了详细的分类和搜索功能,帮助用户快速定位到所需的工具。
AI信息平台
65.1K
国外精选
World Labs
World Labs 是一家专注于空间智能的公司,致力于构建大型世界模型(Large World Models),以感知、生成和与3D世界进行互动。公司由AI领域的知名科学家、教授、学者和行业领导者共同创立,包括斯坦福大学的Fei-Fei Li教授、密歇根大学的Justin Johnson教授等。他们通过创新的技术和方法,如神经辐射场(NeRF)技术,推动了3D场景重建和新视角合成的发展。World Labs 得到了包括Marc Benioff、Jim Breyer等知名投资者的支持,其技术在AI领域具有重要的应用价值和商业潜力。
3D建模
83.1K
Zero To Gpt
zero_to_gpt是一个旨在帮助用户从零基础学习深度学习,并最终实现训练自己的GPT模型的教程。随着人工智能技术走出实验室并广泛应用于各行各业,社会对于能够理解并应用AI技术的人才需求日益增长。本教程结合理论与实践,通过解决实际问题(如天气预测、语言翻译等)来深入讲解深度学习的理论基础,如梯度下降和反向传播。课程内容从基础的神经网络架构和训练方法开始,逐步深入到复杂主题,如变换器、GPU编程和分布式训练。
AI教程
51.9K
ALIEN
ALIEN是一个基于CUDA的专门物理和渲染引擎的人工生命仿真程序。它旨在模拟数字生物在人工生态系统中的行为,并作为进化仿真的平台。该软件项目开源,遵循BSD-3-Clause许可。
AI模型
58.8K
优质新品
MIT MAIA
MAIA(Multimodal Automated Interpretability Agent)是由MIT计算机科学与人工智能实验室(CSAIL)开发的一个自动化系统,旨在提高人工智能模型的解释性。它通过视觉-语言模型的支撑,结合一系列实验工具,自动化地执行多种神经网络解释性任务。MAIA能够生成假设、设计实验进行测试,并通过迭代分析来完善其理解,从而提供更深入的AI模型内部运作机制的洞察。
研究工具
50.2K
Corenet
CoreNet 是一个深度神经网络工具包,使研究人员和工程师能够训练标准和新颖的小型和大型规模模型,用于各种任务,包括基础模型(例如 CLIP 和 LLM)、对象分类、对象检测和语义分割。
AI模型
49.7K
Transformer Debugger (TDB)
Transformer Debugger结合了自动化可解释性和稀疏自编码器技术,支持在编写代码之前进行快速探索,并能够在前向传递中进行干预,以观察其如何影响特定行为。它通过识别对行为有贡献的特定组件(神经元、注意力头、自编码器潜在表示),展示自动生成的解释来说明这些组件为何强烈激活,并追踪组件间的连接以帮助发现电路。
AI开发助手
78.1K
Neural Network Diffusion
Neural Network Diffusion是由新加坡国立大学高性能计算与人工智能实验室开发的神经网络扩散模型。该模型利用扩散过程生成高质量的图像,适用于图像生成和修复等任务。
AI图像生成
80.6K
Infravisn AI
Visnet是一个全面的、无头的、多兼容的神经网络接口框架,主要用于自然语言处理和深度视觉系统。它具有模块化的前端、无服务器架构和多兼容性,并提供了REST API和Websocket接口。它包含了多个核心AI模型,如翻译、车牌识别和人脸特征匹配等。Visnet可广泛应用于监控、无人机检测、图像和视频分析等领域。
开发与工具
59.6K
Instructir
InstructIR 接受图像和人类书写的指令作为输入,通过单一神经模型执行一体化图像修复。在多个修复任务中取得了最先进的结果,包括图像去噪、去雨、去模糊、去雾以及低光图像增强等。🚀 您可以从演示教程开始。查看我们的 GitHub 获取更多信息。
免责声明:请注意,这不是一个产品,因此您会注意到一些限制。此演示需要输入具有某些降级的图像(模糊、噪音、雨、低光、雾)和一个提示,请求应该执行什么操作。由于 GPU 内存限制,如果输入高分辨率图像(2K、4K),应用可能会崩溃。
该模型主要使用合成数据进行训练,因此在真实世界复杂图像上可能效果不佳。然而,在真实世界的雾天和低光图像上效果出奇地好。您还可以尝试一般的图像增强提示(例如,“润色此图像”,“增强颜色”)并查看它如何改善颜色。
AI图像编辑
124.8K
Learning Universal Predictors
通用预测学习器是一种利用元学习的强大方法,能够快速从有限数据中学习新任务。通过广泛接触不同的任务,可以获得通用的表示,从而实现通用问题解决。本产品探索了将最强大的通用预测器——Solomonoff归纳(SI)——通过元学习的方式进行摊销的潜力。我们利用通用图灵机(UTM)生成训练数据,让网络接触到广泛的模式。我们提供了UTM数据生成过程和元训练协议的理论分析。我们使用不同复杂度和普适性的算法数据生成器对神经架构(如LSTM、Transformer)进行了全面的实验。我们的结果表明,UTM数据是元学习的宝贵资源,可以用来训练能够学习通用预测策略的神经网络。
AI模型
48.6K

Bakedavatar
BakedAvatar是一种用于实时神经头像合成的全新表示,可部署在标准多边形光栅化流水线中。该方法从学习到的头部等值面提取可变形的多层网格,并计算可烘焙到静态纹理中的表情、姿势和视角相关外观,从而为实时4D头像合成提供支持。我们提出了一个三阶段的神经头像合成流水线,包括学习连续变形、流形和辐射场,提取分层网格和纹理,以及通过微分光栅化来微调纹理细节。实验结果表明,我们的表示产生了与其他最先进方法相当的综合结果,并显著减少了所需的推理时间。我们进一步展示了从单眼视频中产生的各种头像合成结果,包括视图合成、面部重现、表情编辑和姿势编辑,所有这些都以交互式帧率进行。
AI头像生成
71.5K
Neuralhub
Neuralhub是一个让深度学习更简单的平台,它为AI爱好者、研究人员和工程师提供实验和创新的环境。我们的目标不仅仅是提供工具,我们还在建立一个社区,一个可以分享和协作的地方。我们致力于通过汇集所有工具、研究和模型到一个协作空间,简化当今的深度学习,使AI研究、学习和开发更容易获取。
开发平台
50.0K

Wild2avatar
Wild2Avatar是一个用于渲染被遮挡的野外单目视频中的人类外观的神经渲染方法。它可以在真实场景下渲染人类,即使障碍物可能会阻挡相机视野并导致部分遮挡。该方法通过将场景分解为三部分(遮挡物、人类和背景)来实现,并使用特定的目标函数强制分离人类与遮挡物和背景,以确保人类模型的完整性。
AI图像生成
72.9K

Gaussian SLAM
Gaussian SLAM能够从RGBD数据流重建可渲染的3D场景。它是第一个能够以照片级真实感重建现实世界场景的神经RGBD SLAM方法。通过利用3D高斯作为场景表示的主要单元,我们克服了以往方法的局限性。我们观察到传统的3D高斯在单目设置下很难使用:它们无法编码准确的几何信息,并且很难通过单视图顺序监督进行优化。通过扩展传统的3D高斯来编码几何信息,并设计一种新颖的场景表示以及增长和优化它的方法,我们提出了一种能够重建和渲染现实世界数据集的SLAM系统,而且不会牺牲速度和效率。高斯SLAM能够重建和以照片级真实感渲染现实世界场景。我们在常见的合成和真实世界数据集上对我们的方法进行了评估,并将其与其他最先进的SLAM方法进行了比较。最后,我们证明了我们得到的最终3D场景表示可以通过高效的高斯飞溅渲染实时渲染。
3D建模
48.3K
Mindone
MindOne是一个一站式的AI生成工具App。它整合了多种前沿的AI模型,包括文字生成、图像生成、聊天机器人等功能。用户可以通过MindOne快速生成各种效果的图像,并可以自定义不同的风格和场景。此外,它还内置多种先进的NLP模型,支持智能问答、文本摘要、语音识别等功能。MindOne简单易用的界面设计和合理的价格策略,让普通用户也能无障碍地使用顶级AI技术,开启属于自己的AI之旅。
AI设计工具
69.8K
GPT BOSS
GPT-BOSS可以让您同时访问多个神经网络,并学习如何使用它们来节省时间或提高销售转化率。如果您不知道如何应用它们,我们将教您。
AI开发助手
48.6K

Doodle Dash
Doodle Dash 是一个趣味的在线游戏,它使用神经网络来预测玩家涂鸦的速度。玩家可以在游戏中尽可能快地画出指定的涂鸦,神经网络会根据你的画速给出预测结果。这个游戏基于🤗 Transformers.js 开发。
游戏生成
45.0K
Microsoft Cognitive Toolkit
The Microsoft Cognitive Toolkit(CNTK)是一个开源的商业级分布式深度学习工具。它通过有向图描述神经网络的计算步骤,支持常见的模型类型,并实现了自动微分和并行计算。CNTK支持64位Linux和Windows操作系统,可以作为Python、C或C++程序的库使用,也可以通过其自身的模型描述语言BrainScript作为独立的机器学习工具使用。
AI模型
51.1K
Synaptic.js
Synaptic是一个开源的javascript神经网络库,提供了基本的神经元、网络、训练器和网络构建工具。它可以用于构建和训练各种类型的神经网络,如感知机、长短时记忆网络(LSTM)、液态状态机和Hopfield网络。Synaptic还提供了一些示例和演示,帮助用户学习和使用神经网络。
开发与工具
52.7K
Waifu XL
WaifuXL是一个在浏览器中使用最先进的神经网络对动漫风格的艺术进行高质量图像增强的工具。它支持图像和动图,并且比waifu2x效果更好。该工具提供快速的图像增强、全新的网站界面、优于waifu2x的效果等特点。定价和定位信息请参考官方网站。
图片编辑
113.7K
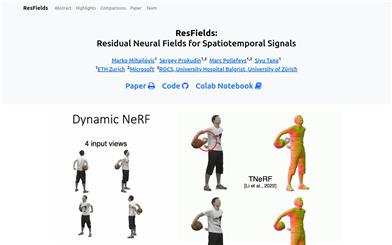
Resfields
ResFields是一类专门设计用于有效表示复杂时空信号的网络。它将时变权重引入多层感知机中,利用可训练的残差参数增强了模型的表达能力。该方法可以无缝集成到现有技术中,并可显著提高各种具有挑战性的任务的结果,如2D视频逼近、动态形状建模和动态NeRF重建等。
AI模型
42.8K
INSTAPAINTING
INSTAPAINTING是一款基于神经网络的照片转画作品的工具。用户可以在几秒钟内将自己的照片转换成艺术品,并通过几次点击让艺术家100%手工绘制并将其送到用户手中。该工具已经集成到我们的即时艺术品预览工具中,用户可以在我们的网站上使用。我们的工具可以应用于油画、宠物肖像、人像、婚礼、风景等多种场景。我们的公司总部位于旧金山。
图片生成
58.5K
Ai Painter
Ai Painter是一款神经网络绘画生成器,可以将您的照片转化为艺术作品或创作抽象艺术。它使用先进的人工智能技术,能够快速、准确地将您的照片转化为绘画作品。Ai Painter不需要任何下载,操作简单,适合所有技能水平的用户。Ai Painter是免费的,您可以在不花费任何费用的情况下使用它。
图片生成
72.9K
Makeml
MakeML是一个无需编写任何代码就可以搭建图像目标检测神经网络的开发工具。它提供了一个简单易用的图形界面,用户只需上传训练集图片,绘制bounding box,设置参数,就可以训练出一个高效的目标检测模型,并导出成CoreML格式在iOS App中使用。MakeML解决了神经网络开发门槛高的痛点,不需要任何机器学习或编程知识,就可以获得强大的深度学习能力。
AI图像检测识别
65.4K
- 1
- 2
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.7K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.7K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
83.4K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.3K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
79.2K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
651.1K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M