%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Diffrhythm
DiffRhythm 是一种创新的音乐生成模型,利用潜在扩散技术实现了快速且高质量的全曲生成。该技术突破了传统音乐生成方法的限制,无需复杂的多阶段架构和繁琐的数据准备,仅需歌词和风格提示即可在短时间内生成长达 4 分 45 秒的完整歌曲。其非自回归结构确保了快速的推理速度,极大地提升了音乐创作的效率和可扩展性。该模型由西北工业大学音频、语音和语言处理小组(ASLP@NPU)和香港中文大学(深圳)大数据研究院共同开发,旨在为音乐创作提供一种简单、高效且富有创造力的解决方案。
音乐生成
74.2K
Structldm
StructLDM是一个结构化潜在扩散模型,用于从2D图像学习3D人体生成。它能够生成多样化的视角一致的人体,并支持不同级别的可控生成和编辑,如组合生成和局部服装编辑等。该模型在无需服装类型或掩码条件的情况下,实现了服装无关的生成和编辑。项目由南洋理工大学S-Lab的Tao Hu、Fangzhou Hong和Ziwei Liu提出,相关论文发表于ECCV 2024。
3D建模
51.1K
SHMT
SHMT是一种自监督的层次化化妆迁移技术,通过潜在扩散模型实现。该技术能够在不需要显式标注的情况下,将一种面部妆容自然地迁移到另一种面部上。其主要优点在于能够处理复杂的面部特征和表情变化,提供高质量的迁移效果。该技术在NeurIPS 2024上被接受,展示了其在图像处理领域的创新性和实用性。
AI设计工具
48.3K
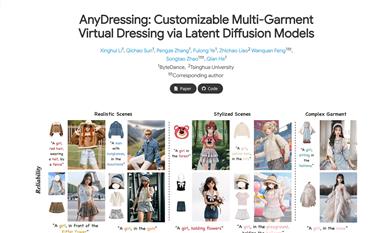
Anydressing
AnyDressing 是一种创新的虚拟试穿技术,通过潜在扩散模型实现多服装的个性化定制。该技术能够根据用户提供的服装组合和个性化文本提示生成逼真的虚拟试穿图像。其主要优点包括高精度的服装纹理细节处理、与多种插件的兼容性以及强大的场景适应能力。AnyDressing 的背景信息显示,它是由字节跳动和清华大学的研究团队共同开发的,旨在推动虚拟试穿技术的发展。该产品目前处于研究阶段,尚未定价,主要面向学术研究和效果展示。
AI设计工具
90.3K
Latentsync
LatentSync 是由字节跳动开发的一款基于音频条件的潜在扩散模型的唇部同步框架。它能够直接利用 Stable Diffusion 的强大能力,无需任何中间运动表示,即可建模复杂的音视频关联。该框架通过提出的时间表示对齐(TREPA)技术,有效提升了生成视频帧的时间一致性,同时保持了唇部同步的准确性。该技术在视频制作、虚拟主播、动画制作等领域具有重要应用价值,能够显著提高制作效率,降低人工成本,为用户带来更加逼真、自然的视听体验。LatentSync 的开源特性也使其能够被广泛应用于学术研究和工业实践,推动相关技术的发展和创新。
视频生成
62.4K
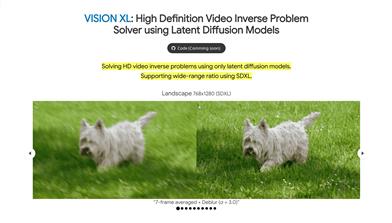
VISION XL
VISION XL是一个利用潜在扩散模型解决高清视频逆问题的框架。它通过伪批量一致性采样策略和批量一致性反演方法,优化了视频处理的效率和时间,支持多种比例和高分辨率重建。该技术的主要优点包括支持多比例和高分辨率重建、内存和采样时间效率、使用开源潜在扩散模型SDXL。它通过集成SDXL,在各种时空逆问题上实现了最先进的视频重建,包括复杂的帧平均和各种空间退化的组合,如去模糊、超分辨率和修复。
视频生成
287.3K

Layerdiffusion
LayerDiffusion 是一种使大规模预训练潜在扩散模型能够生成透明图像的方法。该方法允许生成单个透明图像或多个透明图层。它学习了一种 “潜在透明度”,将 Alpha 通道透明度编码到预训练潜在扩散模型的潜在空间中。通过将添加的透明度调节为潜在偏移,最小程度地改变预训练模型的原始潜在分布,以保留大型扩散模型的生产就绪质量。通过调整潜在空间对其进行微调,可以将任何潜在扩散模型转换为透明图像生成器。我们使用人机协作收集的 100 万个透明图像层对对模型进行训练。我们展示了潜在透明度可以应用于不同的开源图像生成器,或者适应于各种条件控制系统,实现前景 / 背景条件图层生成,联合图层生成,图层内容结构控制等应用。用户研究发现,在大多数情况下(97%),用户更喜欢我们本地生成的透明内容,而不是之前的临时解决方案,比如生成然后抠图。用户还报告说,我们生成的透明图像的质量与 Adobe Stock 等真实商业透明资产相媲美。
AI图像生成
207.6K
Stable Video Diffusion 1.1 Image To Video
Stable Video Diffusion (SVD) 1.1 Image-to-Video 是一个扩散模型,通过将静止图像作为条件帧,生成相应的视频。该模型是一个潜在扩散模型,经过训练,能够从图像生成短视频片段。在分辨率为 1024x576 的情况下,该模型训练生成 25 帧视频,其训练基于相同大小的上下文帧,并从 SVD Image-to-Video [25 frames] 进行了微调。微调时,固定了6FPS和Motion Bucket Id 127的条件,以提高输出的一致性,而无需调整超参数。
AI视频生成
414.6K
Stable Signature
Stable Signature是一种将水印嵌入图像中的方法,它使用潜在扩散模型(LDM)来提取和嵌入水印。该方法具有高度的稳定性和鲁棒性,可以在多种攻击下保持水印的可读性。Stable Signature提供了预训练模型和代码实现,用户可以使用它来嵌入和提取水印。
AI图像编辑
65.4K
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.2K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.7K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
83.4K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.3K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
78.9K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
651.1K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M