%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# computer vision
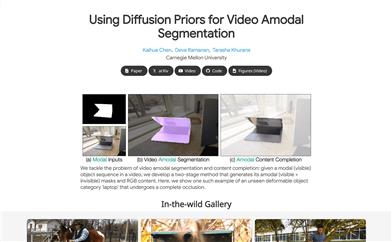
Diffusion Vas
This model for non-visible object segmentation and content completion in videos was proposed by Carnegie Mellon University. It processes sequences of visible objects in a video using a conditional generation approach, leveraging foundational knowledge from video generation models to produce masks and RGB content that include both visible and occluded parts. The main advantages of this technology include its ability to effectively handle highly occluded situations and deformable objects. Additionally, the model outperforms existing state-of-the-art methods across multiple datasets, showing up to a 13% performance improvement in the segmentation of non-visible areas obstructed by objects.
Video Production
48.0K
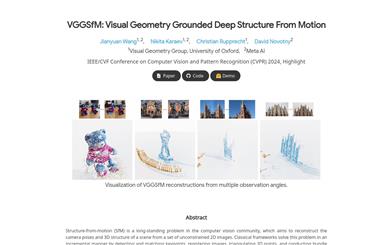
Vggsfm
VGGSfM is a depth learning-driven 3D reconstruction technology aimed at reconstructing the camera pose and 3D structure of a scene from a set of unconstrained 2D images. This technology uses a fully differentiable deep learning framework for end-to-end training. It extracts reliable pixel-level trajectories using depth 2D point tracking technology, while restoring all cameras based on image and trajectory features, and optimizing camera and triangulated 3D points through a differentiable bundle adjustment layer. VGGSfM achieves state-of-the-art performance in three popular datasets: CO3D, IMC Phototourism, and ETH3D.
AI image generation
49.7K
Vastgaussian
VastGaussian is an open-source project for 3D scene reconstruction that leverages 3D Gaussians to model the geometric and appearance information of large-scale scenes. This project is an implementation from scratch and may contain some errors, but it offers a new perspective for the field of 3D scene reconstruction. Key advantages include its ability to process large datasets and the improvements made to the original 3DGS project, enhancing its clarity and usability.
AI 3D tools
52.4K
Fresh Picks
Javavision
JavaVision is a comprehensive visual intelligent recognition project based on Java development. It not only achieves core functions such as PaddleOCR-V4 text recognition, YoloV8 object recognition, face recognition, and image search by image, but also can easily expand to other fields such as voice recognition, animal recognition, and security checks. The features of the project include the use of the SpringBoot framework, multifunctionality, high performance, reliability, easy integration, and flexibility. JavaVision aims to provide Java developers with a comprehensive visual intelligent recognition solution, allowing them to build advanced, reliable, and easily integrated AI applications with the familiar and beloved programming language.
AI image detection and recognition
64.9K
Finecontrolnet
FineControlNet is an official PyTorch implementation for generating images controlled by spatial-aligned text inputs, such as 2D human poses, and instance-specific text descriptions. It can handle a wide range of spatial inputs from simple line drawings to complex human poses. FineControlNet ensures natural interaction and visual coherence between instances and the environment, while retaining the high quality and generalization capabilities of Stable Diffusion, but with enhanced control.
AI image generation
71.8K
ODIN Model
ODIN (Omni-Dimensional INstance segmentation) is a model that uses a transformer architecture for segmentation and labeling on both 2D RGB images and 3D point clouds. It distinguishes 2D and 3D feature operations by iteratively fusing information between 2D views and 3D views. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D, and AI2THOR 3D instance segmentation benchmarks, and achieves competitive performance on ScanNet, S3DIS, and COCO. When using sampled point clouds from 3D meshes instead of perceived 3D point clouds, it surpasses all previous works. As the 3D perception engine in a guided concretization agent architecture, it sets a new state-of-the-art on the TEACh dialogue action benchmark. Our code and checkpoints can be found on the project website.
AI Model
49.7K
Roboflow
Roboflow is a comprehensive platform for building and deploying computer vision models. Used by over 250,000 engineers, it enables the creation of datasets, model training, and deployment to production environments. With Roboflow, you can train a working, state-of-the-art computer vision model in under 24 hours using just a few dozen example images. It provides a suite of functionalities including dataset management, annotation tools, model training, model deployment, and supports integration with various environments and tools.
Development & Tools
53.3K
Featured AI Tools
Chinese Picks

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
151.5K
Fresh Picks

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
112.9K
English Picks

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
132.2K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
99.6K
English Picks

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
66.8K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
90.5K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
662.4K
Chinese Picks

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M