%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Image Description

Describe Anything
The Describe Anything model (DAM) can process specific regions of images or videos and generate detailed descriptions. Its main advantage lies in its ability to generate high-quality localized descriptions through simple markings (points, boxes, scribbles, or masks), greatly enhancing image understanding capabilities in the field of computer vision. The model was jointly developed by NVIDIA and several universities and is suitable for research, development, and practical applications.
Image Generation
49.1K
MILS
MILS is an open-source project released by Facebook Research, designed to demonstrate the capabilities of large language models (LLMs) in handling visual and auditory tasks without any prior training. This technology leverages pre-trained models and optimization algorithms to automatically generate descriptions for images, audio, and video. This breakthrough offers new insights into the development of multi-modal AI, showcasing the potential of LLMs in cross-modal tasks. The model is primarily targeted at researchers and developers, providing them with a powerful tool to explore multi-modal applications. Currently, this project is free and open-source, aimed at advancing academic research and technological development.
AI Model
50.2K
Smolvlm 500M Instruct
SmolVLM-500M, developed by Hugging Face, is a lightweight multimodal model that belongs to the SmolVLM series. Based on the Idefics3 architecture, it focuses on efficient image and text processing tasks. The model can accept image and text inputs in any order and generate text outputs, making it suitable for tasks such as image description and visual question answering. Its lightweight design allows it to operate on resource-constrained devices while maintaining strong performance in multimodal tasks. The model is licensed under the Apache 2.0 license, enabling open-source and flexible usage scenarios.
AI Model
64.6K
Paligemma2 3b Pt 224
Developed by Google, PaliGemma 2 is a vision-language model that combines the capabilities of the SigLIP visual model and the Gemma 2 language model. It is capable of processing both image and text inputs to generate corresponding text outputs. This model excels in various vision-language tasks such as image description and visual question answering. Its main advantages include robust multilingual support, an efficient training architecture, and outstanding performance across diverse tasks. PaliGemma 2 was developed to tackle complex interactions between vision and language, aiding researchers and developers in achieving breakthroughs in their respective fields.
AI Model
48.3K
Paligemma2 3b Pt 448
PaliGemma 2 is a vision-language model developed by Google, inheriting the capabilities of the Gemma 2 model, enabling it to handle image and text inputs to generate text outputs. The model excels in various visual language tasks such as image description and visual question answering. Its main advantages include robust multilingual support, an efficient training architecture, and extensive applicability. This model is suitable for a wide range of applications that require processing visual and textual data, such as social media content generation and intelligent customer service.
AI Model
46.4K
Smart Image Description Generator
The Smart Image Description Generator is an AI-driven online tool that automatically creates accurate, context-sensitive descriptive text for website images, enhancing search engine rankings and improving website SEO and accessibility. It supports over 20 languages and employs cutting-edge AI technology to generate natural, SEO-optimized descriptions that help users increase their image click-through rates, gain more organic traffic, and enhance website visibility.
AI design tools
66.5K
Picwordify
PicWordify is a product that leverages AI technology to automatically generate accurate descriptive text (alt text) for images on websites. It supports over 130 languages, enhancing website accessibility and boosting SEO effectiveness. Through simple code integration, users can quickly add descriptions to both new and existing images, thereby improving search engine rankings and increasing image search traffic. Background information indicates that PicWordify has processed over 5 million images with an accuracy rate of 99.9%, making it a powerful tool for enhancing website SEO and accessibility. In terms of pricing, PicWordify offers both a free plan and paid plans, allowing users to choose the service that best meets their needs.
SEO optimization
56.3K
Joy Caption Batch
joy-caption-batch is a programming model that uses the Joytag Caption tool to batch generate descriptive titles for image files. Currently in the Alpha stage, it analyzes image content to generate corresponding text descriptions using artificial intelligence, helping users quickly understand the content of their images. Key advantages of this tool include batch processing capability, support for custom image directories, and LOW_VRAM_MODE support, allowing it to run on devices with low memory. Additionally, detailed installation and usage instructions are provided to help users get started quickly.
Image Generation
61.3K
AI Describe Pictures
AI Describe Pictures is a platform built using advanced AI models that can quickly generate detailed or brief descriptions for images. Utilizing AI technology, it not only describes the scenes and characters within images but also provides customizable description options according to user needs. This product, by leveraging AI tech, significantly improves the efficiency and accuracy of image descriptions, making it particularly valuable for individuals with visual impairments, content creators, and various scenarios requiring image descriptions.
Image Generation
67.6K
Chinese Picks
Describepic
Leverages AI technology to describe uploaded images, assisting users in quickly generating image explanations. Suitable for content creators and social media users, it enhances the readability and appeal of image content.
Image Generation
155.7K
Florence 2 Large
Florence-2-large, developed by Microsoft, is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of visual and visual-language tasks. The model can interpret simple text prompts to perform tasks such as image description, object detection, and segmentation. It is trained on the FLD-5B dataset, which contains 540 million images with 5.4 billion annotations, making it proficient in multi-task learning. Its sequence-to-sequence architecture enables it to perform well in both zero-shot and fine-tuning settings, proving to be a competitive vision foundation model.
AI image generation
61.5K
Idefics 80b
HuggingFaceM4/idefics-80b-instruct is an open-source multimodal model that can accept both image and text input and generate relevant text output. It excels in tasks like visual question answering and image description, making it a versatile intelligent assistant model. Developed by the Hugging Face team, it's trained on open datasets and is available for free use.
AI Model
67.3K
AI Describe Picture
AI Describe Picture is a revolutionary platform that leverages artificial intelligence to provide rich contextual descriptions for your images. With intuitive upload, interactive chat, and social sharing features, it brings an unprecedented image exploration experience. Step into the new era of AI-driven image description.
Image Generation
83.1K

Genalt Generate AI Alternate Text
GenAlt generates descriptive alternative text for online images, providing assistance to those who need it. Simply right-click on an image and click "Get Alt Text from GenAlt" to obtain a description of the image as its alt text. To view the generated caption and copy it to your clipboard, simply select "Copy AI Image Description from GenAlt". Here are some user testimonials for GenAlt:
1. "GenAlt has been incredibly helpful for me in understanding photos... much better than existing tools." – Accessibility advocate and Twitch streamer
2. "GenAlt is really more helpful than other apps I've found on the internet, really helping me describe pictures better." – High School sophomore Remi
3. "GenAlt is easy to use and helps make social media more accessible to me." – College freshman Aaron
AI image detection and recognition
56.6K
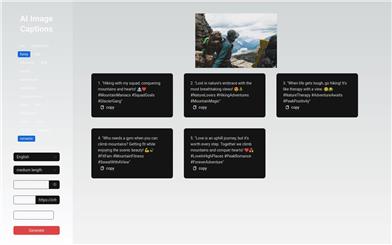
AI Image Captions
AI Image Captions is an AI-powered smart image caption generation tool. It can automatically analyze image content and generate multiple style text descriptions related to the image theme, including humorous, formal, and sales-oriented styles. Users only need to upload an image to get multiple intelligently generated image text descriptions. This product is feature-rich, easy to use, and can greatly improve the efficiency of image text description generation. It is a powerful tool for writers, designers, product managers, and other professionals.
Image Editing
67.6K
Felix Link Captions
Felix Link Captions aims to provide users with image descriptions in various styles, including humorous, lighthearted, and witty. Users can choose descriptions based on their needs, ranging from funny to romantic, professional, and playful. The product offers flexible pricing and focuses on providing personalized image description services.
Document Generator
50.8K
SEED
SEED is a large-scale pre-trained model that, through pre-training and guided fine-tuning on interwoven text and visual data, demonstrates outstanding performance in a wide range of multi-modal understanding and generation tasks. SEED also possesses emerging combinatorial capabilities, such as multi-turn contextual multi-modal generation, much like your AI assistant. SEED also includes SEED Tokenizer v1 and SEED Tokenizer v2, which can convert text into images.
AI Model
61.0K

Genalt Generated AI Image Descriptions
GenAlt uses artificial intelligence to generate descriptive alt text for online images that lack descriptions! Simply right-click on an image, click GenAlt to get the image description, and you'll have a description of the image as its alt text. Please note: GenAlt will display as a brief pop-up window of the title generated for the image.
AI image detection and recognition
48.9K

ALT AI: Add Alt Text To Image Descriptions
ALT AI: Adding Alt text to image descriptions is an accessibility tool that adds alt text to any webpage on the internet. ALT AI aims to improve the web experience for visually impaired users. Using the ALT AI Chrome extension, you can automatically add alt text to every image on a page, replacing any inaccurate existing alt descriptions. Screen readers will read aloud the ALT AI generated alt text, helping users better understand the content on the page.
AI image detection and recognition
60.7K

Minigpt 4
MiniGPT-4 is a visual language understanding model based on advanced large language models, capable of generating detailed image descriptions, creating websites from handwritten sketches, and more. It can also write stories and poems based on given images, provide solutions to problems, and even teach users how to cook based on food photographs. MiniGPT-4 is pre-trained on raw image-text pairs and fine-tuned using dialogue templates and aligned data to improve the coherence and accuracy of its generated outputs. For pricing and other details, please refer to the official website.
AI image generation
49.1K
Featured AI Tools
Chinese Picks

騰訊混元圖像 2.0
騰訊混元圖像 2.0 是騰訊最新發布的 AI 圖像生成模型,顯著提升了生成速度和畫質。通過超高壓縮倍率的編解碼器和全新擴散架構,使得圖像生成速度可達到毫秒級,避免了傳統生成的等待時間。同時,模型通過強化學習算法與人類美學知識的結合,提升了圖像的真實感和細節表現,適合設計師、創作者等專業用戶使用。
圖片生成
91.4K
English Picks

Lovart
Lovart 是一款革命性的 AI 設計代理,能夠將創意提示轉化為藝術作品,支持從故事板到品牌視覺的多種設計需求。其重要性在於打破傳統設計流程,節省時間並提升創意靈感。Lovart 當前處於測試階段,用戶可加入等候名單,隨時體驗設計的樂趣。
AI設計工具
73.1K

Fastvlm
FastVLM 是一種高效的視覺編碼模型,專為視覺語言模型設計。它通過創新的 FastViTHD 混合視覺編碼器,減少了高分辨率圖像的編碼時間和輸出的 token 數量,使得模型在速度和精度上表現出色。FastVLM 的主要定位是為開發者提供強大的視覺語言處理能力,適用於各種應用場景,尤其在需要快速響應的移動設備上表現優異。
AI模型
56.3K

Keysync
KeySync 是一個針對高分辨率視頻的無洩漏唇同步框架。它解決了傳統唇同步技術中的時間一致性問題,同時通過巧妙的遮罩策略處理表情洩漏和麵部遮擋。KeySync 的優越性體現在其在唇重建和跨同步方面的先進成果,適用於自動配音等實際應用場景。
視頻編輯
54.9K
Manus
Manus 是由 Monica.im 研發的全球首款真正自主的 AI 代理產品,能夠直接交付完整的任務成果,而不僅僅是提供建議或答案。它採用 Multiple Agent 架構,運行在獨立虛擬機中,能夠通過編寫和執行代碼、瀏覽網頁、操作應用等方式直接完成任務。Manus 在 GAIA 基準測試中取得了 SOTA 表現,展現了強大的任務執行能力。其目標是成為用戶在數字世界的‘代理人’,幫助用戶高效完成各種複雜任務。
個人助理
1.5M
Trae國內版
Trae是一款專為中文開發場景設計的AI原生IDE,將AI技術深度集成於開發環境中。它通過智能代碼補全、上下文理解等功能,顯著提升開發效率和代碼質量。Trae的出現填補了國內AI集成開發工具的空白,滿足了中文開發者對高效開發工具的需求。其定位為高端開發工具,旨在為專業開發者提供強大的技術支持,目前尚未明確公開價格,但預計會採用付費模式以匹配其高端定位。
開發與工具
145.5K
English Picks

Pika
Pika是一個視頻製作平臺,用戶可以上傳自己的創意想法,Pika會自動生成相關的視頻。主要功能有:支持多種創意想法轉視頻,視頻效果專業,操作簡單易用。平臺採用免費試用模式,定位面向創意者和視頻愛好者。
視頻生成
18.7M
Chinese Picks

Liblibai
LiblibAI是一箇中國領先的AI創作平臺,提供強大的AI創作能力,幫助創作者實現創意。平臺提供海量免費AI創作模型,用戶可以搜索使用模型進行圖像、文字、音頻等創作。平臺還支持用戶訓練自己的AI模型。平臺定位於廣大創作者用戶,致力於創造條件普惠,服務創意產業,讓每個人都享有創作的樂趣。
AI模型
8.0M