%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# 3D Generation
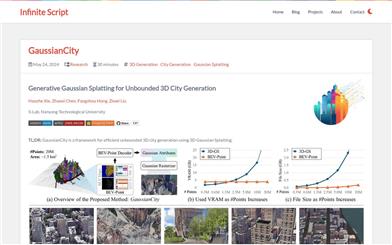
Gaussiancity
GaussianCity is a framework focused on efficiently generating boundless 3D cities, based on 3D Gaussian rendering technology. This technology, through compact 3D scene representation and a spatially aware Gaussian attribute decoder, solves the memory and computational bottlenecks encountered by traditional methods when generating large-scale city scenes. Its main advantage is the ability to quickly generate large-scale 3D cities in a single forward pass, significantly outperforming existing technologies. This product was developed by the S-Lab team at Nanyang Technological University, with the related paper published in CVPR 2025. The code and models have been open-sourced and are suitable for researchers and developers who need to efficiently generate 3D city environments.
3D Modeling
51.3K

Diffsplat
DiffSplat is an innovative 3D generation technology that quickly creates 3D Gaussian point clouds from text prompts and single-view images. This technology leverages a large-scale pre-trained text-to-image diffusion model to efficiently generate 3D content. It addresses the limitations of traditional 3D generation methods concerning dataset size and the ineffective use of 2D pre-trained models, while maintaining 3D consistency. Key advantages of DiffSplat include efficient generation speeds (completed in 1 to 2 seconds), high-quality 3D output, and support for various input conditions. The model has broad prospects in academic research and industrial applications, particularly in scenarios requiring the rapid generation of high-quality 3D models.
3D Modeling
56.6K

TRELLIS
TRELLIS is a native 3D generation model based on a unified structured latent representation and a correction transformer, capable of producing diverse and high-quality 3D assets. The model captures structural (geometric) and texture (appearance) information comprehensively by integrating sparse 3D meshes with dense multi-view visual features extracted from powerful visual foundation models, while maintaining flexibility during the decoding process. TRELLIS can handle up to 2 billion parameters and has been trained on a large dataset of 3D assets containing 500,000 diverse objects. It generates high-quality results conditioned on text or images, significantly surpassing existing methods, including recent approaches of similar scale. TRELLIS also demonstrates flexible output format options and local 3D editing capabilities, which were not provided by previous models. Source code, models, and data will be made available.
3D Modeling
91.9K
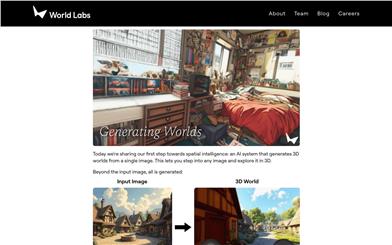
Generating Worlds
This AI system can create a 3D world from a single image, allowing users to immerse themselves in any picture for 3D exploration. This technology improves control and consistency, transforming the way we create films, games, simulators, and other digital expressions. It represents a significant step in spatial intelligence, enabling users to experience various camera effects and 3D effects while exploring classic artworks in real-time within their browser.
3D Modeling
53.8K
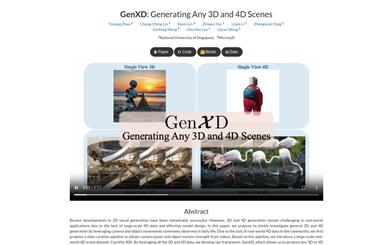
Genxd
GenXD is a framework focused on 3D and 4D scene generation, utilizing common camera and object motion found in everyday life to jointly study general 3D and 4D generation. Due to a lack of large-scale 4D data in the community, GenXD initially proposes a data planning process to extract camera poses and object motion intensity from videos. Based on this process, GenXD introduces a large-scale real-world 4D scene dataset: CamVid-30K. By leveraging all 3D and 4D data, the GenXD framework can generate any 3D or 4D scene. It offers a multi-view-time module that separates camera and object motion, learning seamlessly from 3D and 4D data. Furthermore, GenXD employs masked latent conditions to support various conditional views. GenXD can generate videos that follow camera trajectories and consistent 3D views that can be enhanced to 3D representations. It has undergone extensive evaluation across various real-world and synthetic datasets, demonstrating its effectiveness and versatility in 3D and 4D generation compared to previous methods.
3D Modeling
53.3K
Hunyuan3d 1
Hunyuan3D-1 is a unified framework introduced by Tencent for generating 3D models from text and images. The framework uses a two-stage approach: the first stage employs a multi-view diffusion model to quickly generate multi-view RGB images, while the second stage uses a feed-forward reconstruction model to swiftly construct 3D assets. Hunyuan3D-1.0 strikes an impressive balance between speed and quality, significantly reducing generation time while maintaining the quality and diversity of the generated assets.
3D Modeling
61.0K
Chinese Picks

Tencent Hunyuan 3D
Tencent Hunyuan 3D is an open-source 3D generation model designed to address the shortcomings in generation speed and generalization capabilities of existing 3D generation models. Utilizing a two-stage generation approach, the first stage rapidly generates multi-view images using a multi-view diffusion model, while the second stage quickly reconstructs 3D assets through a feed-forward reconstruction model. The Hunyuan 3D-1.0 model aids 3D creators and artists in automating the production of 3D assets, enabling quick single-image 3D generation, and completing end-to-end production—including mesh and texture extraction—within 10 seconds.
3D modeling
102.4K

Dreammesh4d
DreamMesh4D is a novel framework that combines mesh representation with sparse control deformation techniques to generate high-quality 4D objects from monocular videos. This technology addresses the challenges of spatial-temporal consistency and surface texture quality seen in traditional methods by integrating implicit neural radiance fields (NeRF) or explicit Gaussian drawing as underlying representations. Drawing inspiration from modern 3D animation workflows, DreamMesh4D binds Gaussian drawing to triangle mesh surfaces, enabling differentiable optimization of textures and mesh vertices. The framework starts with a rough mesh provided by single-image 3D generation methods and constructs a deformation graph by uniformly sampling sparse points to enhance computational efficiency while providing additional constraints. Through two-stage learning, it leverages reference view photometric loss, score distillation loss, and other regularization losses to effectively learn static surface Gaussians, mesh vertices, and dynamic deformation networks. DreamMesh4D outperforms previous video-to-4D generation methods in rendering quality and spatial-temporal consistency, and its mesh-based representation is compatible with modern geometric processes, showcasing its potential in the 3D gaming and film industries.
AI video generation
55.5K
Phidias
Phidias is an innovative generative model that utilizes diffusion technology for reference-enhanced 3D generation. This model generates high-quality 3D assets from images, text, or 3D conditions and can complete the process in seconds. It significantly improves generation quality, generalization capability, and controllability through the integration of three key components: a Meta-ControlNet that dynamically adjusts condition strength, dynamic reference routing, and self-reference enhancement. Phidias provides a unified framework for 3D generation using text, images, and 3D conditions, with a variety of application scenarios.
AI image generation
51.3K

Vfusion3d
VFusion3D is a scalable 3D generation model built on a pre-trained video diffusion model. It addresses the challenges of acquiring 3D data and its limited availability by fine-tuning the video diffusion model to generate a large-scale synthetic multi-view dataset, training a feedforward 3D generation model that can quickly create 3D assets from a single image. The model has excelled in user studies, with over 90% of users preferring VFusion3D's generated results.
AI image generation
54.4K

Ouroboros3d
Ouroboros3D is a unified 3D generation framework that integrates multi-view image generation and 3D reconstruction into a single recursive diffusion process. The framework jointly trains the two modules via a self-supervised mechanism, enabling them to adapt to each other and achieve robust inference. During multi-view denoising, the multi-view diffusion model utilizes 3D-aware rendered images from the reconstruction module at the previous timestep as additional conditioning. The combination of the recursive diffusion framework with 3D-aware feedback improves the overall geometric consistency of the process. Experiments demonstrate that the Ouroboros3D framework outperforms both separate training of the two stages and existing methods that combine them at inference time.
AI image generation
66.8K

Interactive3d
Interactive3D is an advanced 3D generation model that provides users with precise control capabilities through interactive design. The model utilizes a two-stage cascading structure, employing different 3D representation methods, allowing users to modify and guide at any intermediate step of the generation process. Its significance lies in the ability to achieve fine control over the 3D model generation process, thereby creating high-quality 3D models that meet specific requirements.
AI 3D tools
51.6K

GRM
GRM is a large-scale reconstruction model that can recover 3D assets from sparse view images in 0.1 seconds and achieve generation in 8 seconds. It is a feed-forward Transformer-based model that can efficiently fuse multi-view information to convert input pixels into pixel-aligned Gaussian distributions. These Gaussian distributions can be back-projected into a dense 3D Gaussian distribution collection representing the scene. Our Transformer architecture and the use of 3D Gaussian distributions unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate that our method surpasses other alternatives in terms of reconstruction quality and efficiency. We also showcase GRM's potential in generation tasks (such as text-to-3D and image-to-3D) by combining it with existing multi-view diffusion models.
AI image generation
62.7K
Stable Video 3D
Developed by Stability AI, Stable Video 3D represents a significant advancement in 3D technology. It offers substantial quality improvements and multi-view support compared to its predecessor, Stable Zero123. This model can generate track videos based on a single input image without any camera data and create 3D videos along specified camera paths.
AI video generation
155.4K

LGM
LGM is a novel framework for generating high-resolution 3D models from textual prompts or single-view images. Its key insights include: (1) 3D Representation: We propose a multi-view Gaussian feature as an efficient yet powerful representation that can be fused for differentiable rendering. (2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operation for multi-view images, which can be utilized to generate from text or single-view image inputs using multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our method. Notably, we achieve high-resolution 3D content generation while maintaining fast rendering speed for 3D objects, even when training resolution is increased to 512x512.
3D Modeling
76.2K
Hexagen3d
HexaGen3D is an innovative approach to generating high-quality 3D assets from text prompts. It leverages a large pre-trained 2D diffusion model, fine-tuned from a pre-trained text-to-image model, to jointly predict six orthogonal projections and corresponding latent trimeshes. These latent values are then decoded to generate textured meshes. HexaGen3D does not require optimization for each sample and can infer high-quality, diverse objects within 7 seconds from text prompts, providing a better balance of quality and latency compared to existing methods. Additionally, HexaGen3D demonstrates strong generalization capabilities for novel objects or combinations.
AI 3D tools
53.0K

Gpteval3d
GPTEval3D is an open-source tool for evaluating 3D generation models. Based on GPT-4V, it enables automatic evaluation of text-to-3D generation models. It can calculate the ELO score of the generated models and compare them with existing models for ranking. This user-friendly tool supports custom evaluation datasets, allowing users to fully leverage the evaluation capabilities of GPT-4V. It serves as a powerful tool for researching 3D generation tasks.
AI Model Evaluation
80.0K
Featured AI Tools
Chinese Picks

騰訊混元圖像 2.0
騰訊混元圖像 2.0 是騰訊最新發布的 AI 圖像生成模型,顯著提升了生成速度和畫質。通過超高壓縮倍率的編解碼器和全新擴散架構,使得圖像生成速度可達到毫秒級,避免了傳統生成的等待時間。同時,模型通過強化學習算法與人類美學知識的結合,提升了圖像的真實感和細節表現,適合設計師、創作者等專業用戶使用。
圖片生成
91.6K
English Picks

Lovart
Lovart 是一款革命性的 AI 設計代理,能夠將創意提示轉化為藝術作品,支持從故事板到品牌視覺的多種設計需求。其重要性在於打破傳統設計流程,節省時間並提升創意靈感。Lovart 當前處於測試階段,用戶可加入等候名單,隨時體驗設計的樂趣。
AI設計工具
73.1K

Fastvlm
FastVLM 是一種高效的視覺編碼模型,專為視覺語言模型設計。它通過創新的 FastViTHD 混合視覺編碼器,減少了高分辨率圖像的編碼時間和輸出的 token 數量,使得模型在速度和精度上表現出色。FastVLM 的主要定位是為開發者提供強大的視覺語言處理能力,適用於各種應用場景,尤其在需要快速響應的移動設備上表現優異。
AI模型
56.3K

Keysync
KeySync 是一個針對高分辨率視頻的無洩漏唇同步框架。它解決了傳統唇同步技術中的時間一致性問題,同時通過巧妙的遮罩策略處理表情洩漏和麵部遮擋。KeySync 的優越性體現在其在唇重建和跨同步方面的先進成果,適用於自動配音等實際應用場景。
視頻編輯
54.9K
Manus
Manus 是由 Monica.im 研發的全球首款真正自主的 AI 代理產品,能夠直接交付完整的任務成果,而不僅僅是提供建議或答案。它採用 Multiple Agent 架構,運行在獨立虛擬機中,能夠通過編寫和執行代碼、瀏覽網頁、操作應用等方式直接完成任務。Manus 在 GAIA 基準測試中取得了 SOTA 表現,展現了強大的任務執行能力。其目標是成為用戶在數字世界的‘代理人’,幫助用戶高效完成各種複雜任務。
個人助理
1.5M
Trae國內版
Trae是一款專為中文開發場景設計的AI原生IDE,將AI技術深度集成於開發環境中。它通過智能代碼補全、上下文理解等功能,顯著提升開發效率和代碼質量。Trae的出現填補了國內AI集成開發工具的空白,滿足了中文開發者對高效開發工具的需求。其定位為高端開發工具,旨在為專業開發者提供強大的技術支持,目前尚未明確公開價格,但預計會採用付費模式以匹配其高端定位。
開發與工具
145.7K
English Picks

Pika
Pika是一個視頻製作平臺,用戶可以上傳自己的創意想法,Pika會自動生成相關的視頻。主要功能有:支持多種創意想法轉視頻,視頻效果專業,操作簡單易用。平臺採用免費試用模式,定位面向創意者和視頻愛好者。
視頻生成
18.7M
Chinese Picks

Liblibai
LiblibAI是一箇中國領先的AI創作平臺,提供強大的AI創作能力,幫助創作者實現創意。平臺提供海量免費AI創作模型,用戶可以搜索使用模型進行圖像、文字、音頻等創作。平臺還支持用戶訓練自己的AI模型。平臺定位於廣大創作者用戶,致力於創造條件普惠,服務創意產業,讓每個人都享有創作的樂趣。
AI模型
8.0M