%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)


Sana 1600M 512px MultiLing
Overview :
Sana is a text-to-image framework developed by NVIDIA, capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at an extremely fast speed, featuring strong text-image alignment capabilities and deployable on laptop GPUs. The model is based on linear diffusion transformers, utilizing a fixed pre-trained text encoder and a space-compressed latent feature encoder, supporting mixed prompts in English, Chinese, and emojis. The key advantages of Sana include high efficiency, high-resolution image generation capability, and multilingual support.
Target Users :
The target audience includes researchers, artists, designers, and creative professionals. The Sana model is particularly suited for professionals who need to create images in multilingual environments, thanks to its high-resolution image generation capabilities and multilingual support. Additionally, its rapid synthesis and laptop GPU deployment capabilities make it ideal for individual users engaged in artistic creation and research.
Use Cases
? Generate an image of the Great Wall in a traditional Chinese style using the Sana model based on a text prompt.
? Create an image of a tiger wearing a t-shirt and playing the saxophone using the Sana model.
? Generate an image depicting a lion teaching a tiger to catch butterflies through the Sana model.
Features
? High-resolution image generation: Capable of generating images up to 4096×4096 in resolution.
? Multilingual support: Supports mixed prompts in English, Chinese, and emojis.
? Fast synthesis: Synthesizes high-resolution, high-quality images at an extremely rapid pace.
? Laptop GPU deployment: Designed for easy deployment on laptop GPUs for personal use.
? Linear diffusion transformer: Based on linear diffusion transformer technology to enhance image generation efficiency.
? Pre-trained text encoder: Utilizes a fixed pre-trained text encoder to improve text-to-image conversion accuracy.
? Space-compressed latent feature encoder: Employs a space-compressed latent feature encoder to optimize model performance.
? Suitable for research and artistic creation: Ideal for generating artistic works and other creative processes.
How to Use
1. Visit the Hugging Face website and locate the Sana_1600M_512px_MultiLing model page.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Read the model description and usage guidelines to understand its capabilities and limitations.
3. Prepare the appropriate text prompts based on the type of images you want to generate.
4. Use the API or code library provided by the model to input the text prompts and initiate the image generation process.
5. Wait for the model to process and generate the images; check if the generated images meet your expectations.
6. If necessary, adjust the text prompts or model parameters and regenerate the images for better results.
7. Utilize the generated images for artistic creation, design, or other research purposes.







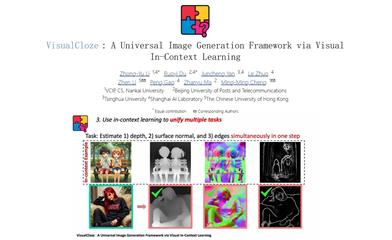
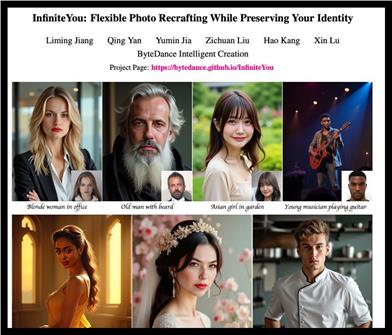

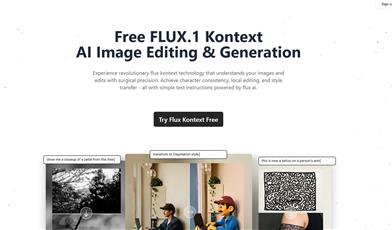

Featured AI Tools

Face To Many
Face to Many can transform a facial photo into multiple styles, including 3D, emojis, pixel art, video game style, clay animation, or toy style. Users simply upload a photo and choose the desired style to effortlessly create amazing and unique facial art. The product offers various parameters for user customization, such as noise intensity, prompt intensity, depth control intensity, and InstantID intensity.
Image Generation
4.8M
English Picks
Domoai
DomoAI is an image creation tool that offers a variety of pre-set AI models, allowing users to effortlessly achieve a consistent artistic style across all their projects. Its user-friendly and efficient design enables quick mastery, helping users craft exceptional visual assets. With DomoAI, users can experiment quickly and efficiently, boosting their creativity. Additionally, DomoAI's text-to-art feature transforms imagination into reality in just 20 seconds, bringing anime dreams to life.
Image Generation
2.7M