%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Understanding Video Transformers
Overview :
This paper investigates the problem of conceptual interpretability for video Transformer representations. Specifically, we aim to explain the decision-making process of video Transformers based on high-level spatio-temporal concepts that are automatically discovered. Previous research on concept-based interpretability has primarily focused on image-level tasks. In contrast, video models handle the additional time dimension, increasing complexity and posing challenges in identifying dynamic concepts that evolve over time. In this work, we systematically address these challenges by introducing the first video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an effective unsupervised method for identifying video Transformer representation units (concepts) and rank their importance in the model output. The obtained concepts exhibit high interpretability, revealing the spatio-temporal reasoning mechanisms and object-centric representations within black-box video models. Through joint analysis on diverse supervised and self-supervised representations, we discover that some of these mechanisms are prevalent across video Transformers. Finally, we demonstrate that VTCD can be used to improve the performance of models on fine-grained tasks.
Target Users :
Used to explain the decision-making process of video Transformers and improve model performance
Use Cases
Explain the decision-making process of video Transformers
Improve the performance of video models
Discover universal mechanisms within video Transformers
Features
Unsupervised video Transformer Concept Discovery
Ranking the importance of video Transformer concepts
Revealing the spatio-temporal reasoning mechanisms and object representations in video Transformers

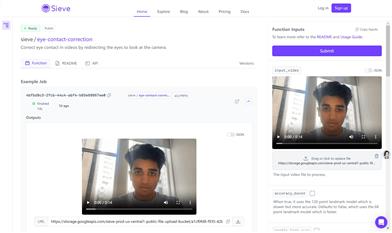

Featured AI Tools
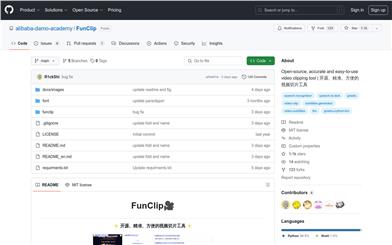
Funclip
FunClip is a fully open-source, locally deployed automated video editing tool. It utilizes the FunASR Paraformer series of open-source models from Alibaba's TGETHER Lab for video voice recognition. Users can then freely select text segments or speakers from the recognized results, and clicking the crop button retrieves the corresponding video clip. FunClip integrates Alibaba's open-source industrial-grade Paraformer-Large model, one of the best-performing open-source Chinese ASR models currently available, and accurately predicts timestamps in an integrated manner.
AI Video Editing
235.4K
Chinese Picks
Kuaiying
Developed by Kuaishou, KuaiYing is a video editing application that offers a comprehensive suite of video editing features, including cutting, audio, subtitles, special effects, and more. It aims to help users easily create engaging and professional video content. It features an AI-powered anime video function that can transform videos into anime styles, offering various options like anime style, national style, and Japanese anime style. Additionally, KuaiYing boasts AI creation tools such as AI drawing, AI text-to-image, and an AI copywriting library to assist users in their creative endeavors. KuaiYing also provides a creative center to help users view data, find inspiration, and offers a powerful resource library including stickers and trending content to enhance user engagement.
AI Video Editing
217.8K